
An overview of monitoring tools: purpose and challenges
Monitoring tools help us to know the current state, whether it is normal or exceptional. They allow us to know the causes that led us to that state, and even allow us to forecast the future basing on data.
But all these platforms face a number of technological challenges that depend heavily on the performance of the underlying database:
- High insertion rates: A monitoring system must be able to continuously receive information from its agents, probes, or third-party systems; process it; and store KPIs, events and other significant incoming data. These systems require low latency and as constant as possible.
- KPI calculation: A recurrent KPI calculation is performed during the data processing. These metrics are usually generated in real time or quasi-real time, from the information of a large number of different elements.
- Insertion/Recovery of historical time series: The third challenge is to provide an agile access to the historical series. This data is used in a general way within a monitoring application: reports, graphs, event calculation, forecasting… A low performance impacts globally on the application performance.
- Scaling: Historical data volumes are very important, even in very modest deployments. Systems are faced with the need to be able to scale horizontally without increasing the complexity of the application, nor increasing the cost per monitored element.
Why is LeanXcale an optimal choice as a database for a monitoring solution?
High insertion rates
LeanXcale is an ultra-fast database due to:
- Ultra-Efficient Storage Engine (KiVi): KiVi’s mono-threaded design avoids context switching, thread synchronization and remote NUMA memory access, as a result of over 20 years of operating system research.
- Dual Interface: KiVi is a relational key-value data store, and LeanXcale provides SQL and NoSQL interfaces. The NoSQL interface is extremely fast (~50 times less latency than MariaDB).

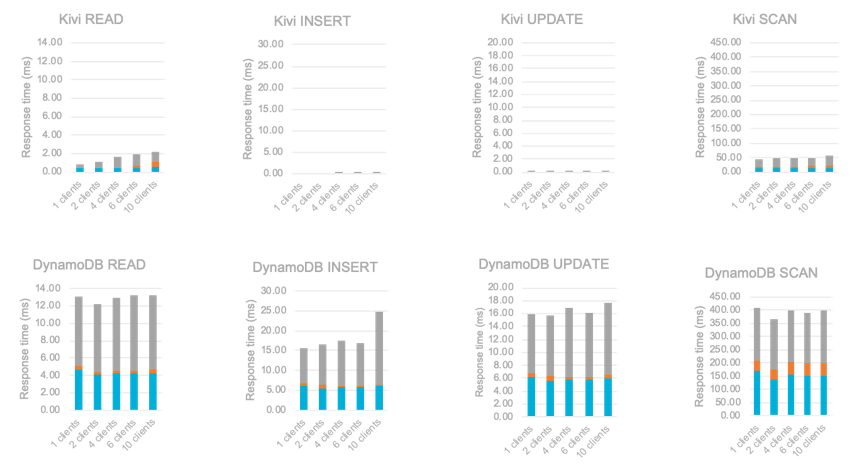
KPI calculation
As you can see in this document, online aggregation can bring about extraordinary improvements: calculating the insertion time aggregates in PostgreSQL and in LeanXcale for 15 million rows, it can mean going from 4.21 hours to 2.65 minutes.
Time series recovery
- New data structure: There is a dichotomy between SQL databases and key-value data stores. SQL databases, which use B+ trees, work best for queries. Key-value data stores, which use LSM trees, are more efficient for data ingestion. LeanXcale has developed a new data structure that is as efficient as B+ trees for range queries and LSM trees for updates and random insertions.
- Bi-dimensional partitioning: LeanXcale is optimized to handle time series thanks to the partitioning of the data. LeanXcale divides the data in such a way that memory is used efficiently, preventing continuous I/O access, and increasing the location of information in the subsequent search.
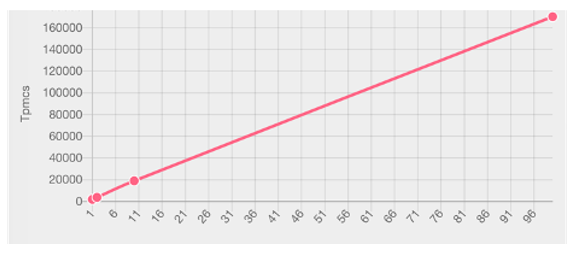
As you can see in this demo, the bi-dimensional partitioning allows constant ingestion regardless of the volume of previously stored data. In this demo, 168 million records are inserted in less than 30 minutes in two m5.xlarge machines.
Large volumes
- Scalable and distributed architecture: LeanXcale is divided into three tiers: storage, transactional, and query engine. These three layers are fully distributed and scale independently, on the same or different servers.
- Distributed Storage and Parallel Scanning: LeanXcale improves queries on large data volumes, reducing latency and leveraging the user’s infrastructure by parallelizing scanning operations over multiple storage engines.
- Horizontal linear scalability: Traditional relational databases scale in a logarithmic way, or not scale at all. LeanXcale has developed the patented “Iguazú” technology. With it you can scale linearly while maintaining ACID features without creating bottlenecks, thanks to a distributed algorithm that processes transactions in parallel.
Business benefits
Thanks to the simplification of the underlying architectures of a monitoring tool, LeanXcale presents some business values:
- Shorter Time-To-Market (TTM): The engineering team only has to develop on a SQL-based database, instead of using multiple technologies, which allows for shorter development times.
- Lower Total Cost of Ownership (TCO): LeanXcale allows the use of a simple architecture. This means fewer servers, fewer different licenses, and fewer experts in different technologies. Additionally, LeanXcale offers an annual subscription fee at a reduced cost.
- From MVP to global deployment: LeanXcale scales linearly depending on the needs of the business at any given time. Therefore, LeanXcale ensures that the architecture never needs to be changed: no matter how much the business grows, only new nodes need to be added to the LeanXcale cluster.
Conclusions
We invite you to check it out by requesting the free two-week trial!
Written by
Juan Mahíllo

Juan is a telecommunications engineer from UPM. After starting his career in large companies in the NPM sector, he founded his own company in the Application Performance Monitoring sector. Now he is CRO at LeanXcale.