

INTRODUCTION
Today, companies are storing more data compared to years ago, which creates a need for systems capable of storing and processing so much information. The data generated and stored by companies has been exponentially growing during the last years. By 2025, it is estimated that 463 exabytes of data will be generated each day globally. The best-known technology to store and process data is a database. However, traditional databases cannot manage that huge amounts of data. An alternative exists, called NoSQL, but it includes multiple problems:
- The interfaces of the NoSQL platforms are different from traditional SQL databases, which implies a significant shift for a company’s product.
- NoSQL databases are typically hard to configure for large deployments.
- Most NoSQL databases do not guarantee ACID transactions, which impacts how these databases are used by applications.
- The few that do guarantee ACID transactions have scalability problems. In many cases, the system might not be capable of growing as much as the workload requires.
LeanXcale is a database that solves these problems without impacting current systems:
- LeanXcale offers an SQL interface that follows the query language standard to make it easier to adapt to the new database system. Companies won’t need to spend much effort refactoring products to adapt to this scalable database.
- Being easy to configure, LeanXcale offers an on-premise instance entirely configured and ready for use out of the box.
- LeanXcale guarantees full ACID transactions, so you won’t need to adapt your product.
- Based on its patented system, LeanXcale can scale as much as the workload requires while maintaining full ACID transactions, so companies can grow as much as needed.
In this article, I test the horizontal scalability of the LeanXcale database using the TPC-C like benchmark.
LEANXCALE CHARACTERISTICS
LeanXcale is comprised of components with distributed capabilities. All are designed and implemented to be distributed and highly available, allowing LeanXcale to run either on a single instance or many more. These components are distinguished as Meta or Data node instance types.
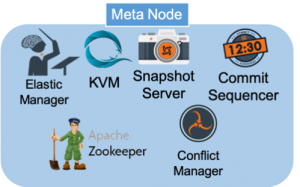
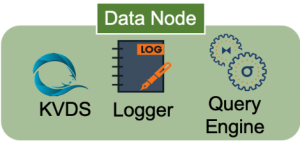
For the scalability benchmark applied here, the Data node is most relevant because it allows us to distribute the storage engine across multiple instances. The components of the Kivi Data Store (KVDS) and Query Engine can run while distributing the load across multiple instances. Kivi, the LeanXcale storage engine, can be fully distributed as all the tables can be split and distributed across many KVDS instances. Consequently, the storage engine can run on many nodes without any tradeoffs. At the same time, the Query Engine can run as many instances as is needed depending on the workload of the system as well as maintain full ACID transactions while scaling. In addition, it can coordinate work for large queries by using processing units on each Query Engine instance. With this, the Query Engine can run HTAP workloads keeping full ACID transactions. For this demonstration, we run the TPC-C benchmark that makes use of the OLTP (Online Transaction Processing) transactions.
As described above, LeanXcale is a distributed database, and it offers disruptive features. Scalability is the most relevant for this benchmark, although we also use the dual interface through which LeanXcale provides a key-value interface offering fast insertions, gets and scans, and an SQL interface through a JDBC driver. This key-value interface populates the database and prepares all data required to run the clients of the benchmark. Through the JDBC interface, the client of the benchmark runs the SQL queries.
You can get a more in-depth description of LeanXcale capabilities here.
THE TPC-C BENCHMARK
This benchmark is an OLTP benchmark similar to the one proposed by the Transaction Processing Performance Council to emulate sales in a large company represented by different warehouses. The number of warehouses has a direct relation to the number of clients (with ten clients per warehouses) querying the system and the size of the database (approximately 500k tuples per warehouse). This benchmark can run with different data and transaction sizes by increasing the number of warehouses and clients. The performance metric reported by this benchmark measures the number of orders that can be fully processed per minute, expressed in new order transactions per minute (notpm).
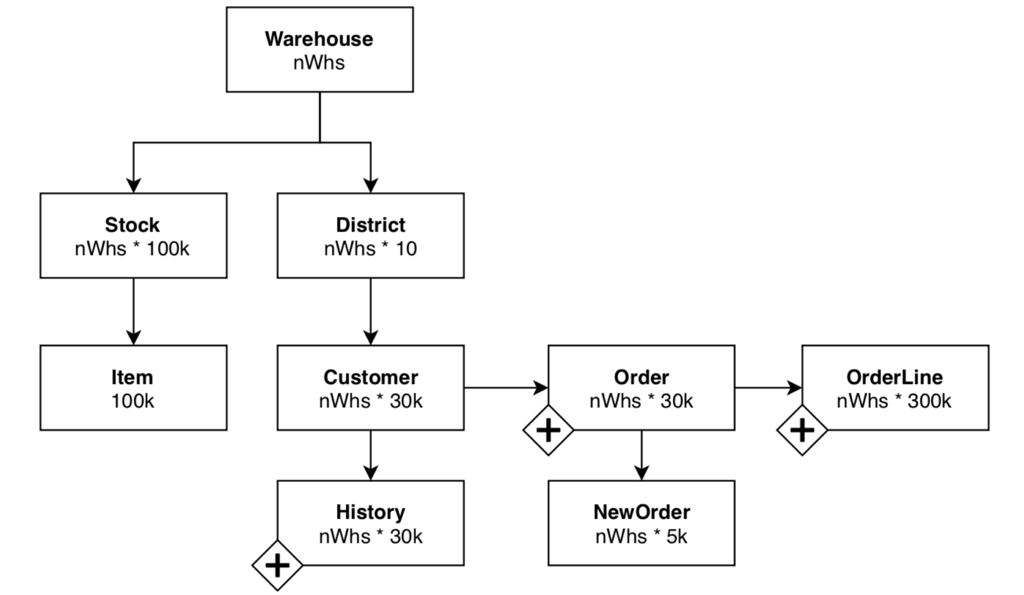
Figure 1 includes a diagram with the dependencies between the tables used by the TPC-C benchmark. All the tables have a fixed size determined by the number of warehouses, except for Order line, History, and Order. These three tables have a set size when the benchmark starts, and then grow as the benchmark progresses.
This benchmark simulates different user queries, each running some linked queries with the following percentages:

To test the scalability of LeanXcale, we run a distribution with a different number of data nodes, from 1 to 100. The meta node and all data nodes used for this demo are homogeneous r5d.xlarge AWS instances and the TPC-C clients are started on t2.xlarge AWS instances.
On each data node, we populate the benchmark with 200 warehouses, then run the benchmark with 1, 20, and 100 data nodes. Each data node includes a Query Engine responsible for managing the transactional workload for a fraction of the clients. The data nodes also have an instance of the storing engine, KVDS. Each KVDS instance oversees a fraction (200 warehouses) of the entire dataset.
The result of this benchmark is the number of new order operations (around 45% of the total operations of the benchmark) and is expressed as tpmCs. The benchmark passes if the number of tpmCs is around 12,5 tpmCs per warehouse.
The following chart shows the tpmCs obtained with the following configurations:
- 1 data node with 200 warehouses: 2.500 tpmCs
- 20 data nodes with 4.000 warehouses: 50.000 tpmCs
- 100 data nodes with 20.000 warehouses: 250.000 tpmCs
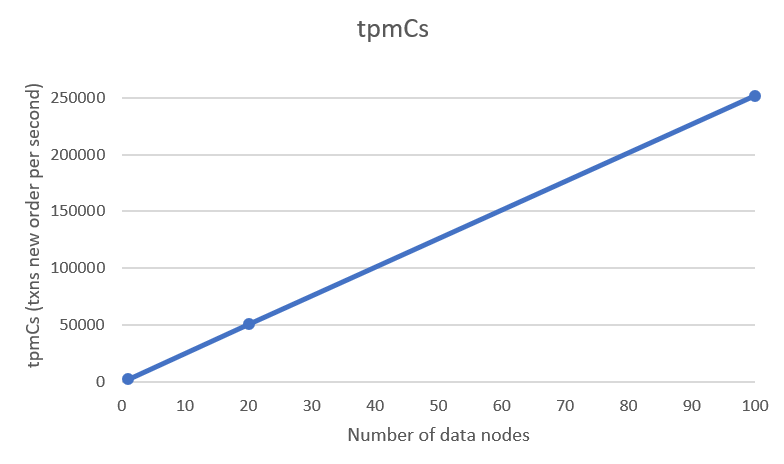
With this experimentation, we confirmed that LeanXcale has scale-out properties by proving that with 100 data nodes, its performance increases 100 times than with just a single data node. This makes LeanXcale capable of processing any transactional workload by dimensioning the system.
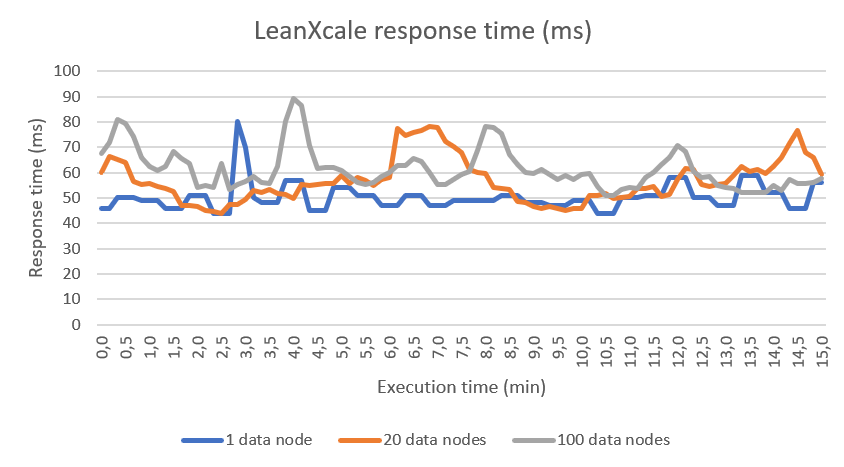
The number of transactions of the system is relevant for the TPC-C benchmark as well as the response time. With LeanXcale, the average response time (during 15 mins) is independent of the number of warehouses and data nodes in the deployment. The following chart shows the response time during the last 15 minutes of the TPC-C benchmark. As can be seen, the response time maintains a maximum of 80 ms and a minimum of 45 ms.
Now that we demonstrated the linear scalability of LeanXcale, we devote future posts to test other LeanXcale features, such as real-time or geohash, but in the meantime you can get more info about LeanXcale from their whitepapers here.
WRITTEN BY

Diego Burgos Sancho
Software Engineer at LeanXcale
After working at the Distributed Systems Lab at the Technical University of Madrid as a computer scientist, I joined LeanXcale to build one of the most interesting distributed systems ever developed. At LeanXcale, I’m performing research through an industrial PhD at the Technical University of Madrid.