

This post demonstrates how to combine the use of Apache Spark and LeanXcale to build a simple movie-recommendation engine, taking advantage of the LeanXcale Spark connector and Spark’s machine learning features. This tutorial is based on the training exercises on collaborative filtering in the Spark ML documentation. However, file-based storage is replaced by database tables, which allows us to store the recommendations and query them later using SQL.
The concept behind this recommender is to recommend some movies to a new user from a set of movies rated by different users. In essence, this involves rating a complete movie set and recommending movies with higher ratings.
To estimate this rating, we will ask the new user to rate some movies; the algorithm will then extrapolate the ratings for the rest of them.
The subsequent steps are:
- Read data from LeanXcale to Spark.
- Ask the new user for some ratings.
- Process this data using the Spark ALS engine to build the recommendations.
- Move the recommendations from Spark to LeanXcale for storage.
PREREQUISITES
To follow this tutorial, you will need:
- An Apache Spark installation. The version that we will use is 2.4.5, and you can find the install instructions here.
- A running instance of the LeanXcale database. You can request a free trial here.
- The LeanXcale Spark connector and the Java KiVi Direct API, which can be found here. For this tutorial, we will use version 1.4.
SETTING THE PROJECT UP
The complete code can be found in our gitlab repository.
The project will be developed as a standard maven project, so the first step is to define a pom.xml, with following dependencies:
<dependencies>
<!-- LeanXcale Spark connector dependency -->
<dependency>
<groupId>com.leanxcale</groupId>
<artifactId>spark-lx-connector</artifactId>
<version>1.4</version>
</dependency>
<!-- Spark dependency -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>2.4.4</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.12</artifactId>
<version>2.4.5</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.1</version>
<scope>provided</scope>
</dependency>
</dependencies>
We have included the LeanXcale connector dependency, as well as the Spark dependencies for an ml Spark project.
If you have not installed the LeanXcale Spark connector package yet, you can download the jar and install it in your local repository as follows:
mvn install:install-file -Dfile=spark-lx-connector-1.4.jar-DgroupId=com.leanxcale -DartifactId=spark-lx-connector -Dversion=1.4 -Dpackaging=jar
The dataset that we will use consists of three tables:
- MOVIES, which contains the list of movies to be rated, with the following scheme:
- ○ Movie_id: Id, as an integer.
○ Title: Movie title, as a string.
○ Genre: Genres, as a comma-separated string list. - RATINGS, which contains the recommendations made by users, with the following scheme:○ User_id: Id of the rating user, as an integer.
○ Movie_id: Id of the movie rated, as an integer (points to movies table).
○ Rating: An integer—between 0 (not seen) and 5 (fabulous)—which represents the rating provided by the user.
○ Timestamp: A timestamp, representing the moment when the movie was rated. - RESULT_RECOMMENDATIONS, which contains the results of the process, along with the recommendations predicted for the target user, with the following scheme:○ User_id
○ Movie_id
○ Rating
The movies and ratings tables have been populated using the dataset of the MovieLens project, as in the original tutorial. This is not within the scope of this post, but if you wish to, you can find a simple loader to take the :: separated files of the MovieLens project into the LeanXcale tables in the DataLoader class in the gitlab project.
For our tests, the 1M size dataset has been used, but you can use the one you prefer.
WRITING THE CODE
Loading data
First, we have to start a Spark session in the usual way:
SparkSession spark = SparkSession.builder().appName("Movie ALS recommender").getOrCreate();
Then, we have to load the dataset from LeanXcale. To do this, we will load a standard Spark Dataset object, indicating that the format is a LeanXcale Datasource, and configuring the endpoint and the table name through the load() method options.
We will do this for the ratings table.
Dataset<Row> ratings = spark.read()
.format(LeanxcaleDataSource.SHORT_NAME)
.option(LeanxcaleDataSource.URL_PARAM, DataLoader.LX_URL)
.option(LeanxcaleDataSource.TABLE_PARAM,DataLoader.RATINGS_TABLE)
.option(LeanxcaleDataSource.DATABASE_PARAM, DataLoader.DATABASE_NAME)
.option(LeanxcaleDataSource.TRANSACTIONAL,"true")
.load()
.cache();
It is important to note that the LeanXcale Datasource requires the following parameters:
- URL_PARAM: Represents an endpoint to your LeanXcale installation.
- DATABASE_PARAM: Represents the name of the database that the table to load is stored in.
- TABLE_PARAM: Represents the name of the table that will be loaded into the Spark dataset.
- TRANSACTIONAL: This is an optional parameter (default false), which indicates that the access to LeanXcale will be fully transactional (ACID).
Training the model
Now, we have to build the model using the ALS object included in the Spark ML package, indicating which columns in the dataset correspond to the user, item, and rating columns of the model.
To avoid stack-overflow errors when using ALS, owing to excessive recursion on the codebase, we will configure the following checkpoints:
spark.sparkContext().setCheckpointDir("/tmp/checkpoint");
ALS als = new ALS()
.setCheckpointInterval(2)
.setUserCol(DataLoader.USER_ID)
.setItemCol(DataLoader.MOVIE_ID)
.setRatingCol(DataLoader.RATING);
To validate the accuracy of the model, we split the dataset into a training dataset and a validation dataset, using a random split with the proportion of 0.80 and 0.20, respectively. Further, we define a grid of parameters to let the training search for the best configuration.
To evaluate the best configuration, we will use the mean-squared error (as is indicated in “rmse” constant).
ParamMap[] paramMap = new ParamGridBuilder()
.addGrid(als.regParam(), new double[]{0.1, 10.0})
.addGrid(als.rank(), new int[]{8, 10})
.addGrid(als.maxIter(), new int[]{10, 20})
.build();
RegressionEvaluator evaluator = new RegressionEvaluator()
.setMetricName("rmse")
.setLabelCol(DataLoader.RATING)
.setPredictionCol("prediction");
TrainValidationSplit trainValidationSplit = new TrainValidationSplit()
.setEstimator(als)
.setTrainRatio(0.8)
.setEvaluator(evaluator)
.setEstimatorParamMaps(paramMap);
TrainValidationSplitModel bestModel = trainValidationSplit.fit(ratings);
At this point, we have to add personal ratings from the target user to the training dataset, because we want to force the model to be trained with this information.
To do this, I have used a “data retriever,” which asks the users their preference using the standard input and output. This is not within the scope of this post, but you can find the code in the RatingsRetriever class in the git project.
int numUserRatings = 8; Dataset<Row> personalRatings = RatingsRetriever.retrieveRatings(numUserRatings, spark);
Now we have to re-train the model with the user data and the best parameters found in the previous training:
Dataset<Row> totalRatings = ratings.union(personalRatings);
ALSModel model = als.fit(totalRatings,bestModel.extractParamMap());
model.setColdStartStrategy("drop");
Making predictions
With the model trained and validated, we can use some ALSModel methods to make predictions; in our case, we want to retrieve the ten best predictions for our single target user, identified by the user_id 0.
// Generate top 10 movie recommendations for a specified set of users
Dataset<Row> users = spark.createDataFrame(Collections
.singletonList(RowFactory.create(0L)),
new StructType(new StructField[]{new
StructField(als.getUserCol(),DataTypes.LongType,false,Metadata.empty())}));
Dataset<Row> userSubsetRecs = model.recommendForUserSubset(users, 10).cache();
This method will generate a dataset with a user attribute, and an array of tuples (movie, rating) with the predicted rating for the most rated movies.
In order to store it in a relational table we will flatten it, generating a new dataset of tuples (user_id, movie_id, predicted_rating).
Dataset<Row> result = userSubsetRecs.select(col(als.getUserCol()),explode(col
("recommendations")).as("rec")).select(col(als.getUserCol()),
col("rec." + als.getItemCol()),col("rec.rating").cast(
DataTypes.IntegerType));
Storing the results
Once the result dataset has been calculated, we can save it into LeanXcale using the dataset write() method, configuring the format, the endpoint, and the table as in the read step.
result.write()
.format(LeanxcaleDataSource.SHORT_NAME).mode(SaveMode.Overwrite)
.option(LeanxcaleDataSource.URL_PARAM, DataLoader.LX_URL)
.option(LeanxcaleDataSource.DATABASE_PARAM, DataLoader.DATABASE_NAME)
.option(LeanxcaleDataSource.TRANSACTIONAL,"true")
.saveAsTable("result_recommendations");
EXECUTING THE CODE
Generating the package
If you have configured the maven project correctly, you can generate a jar with your code, as follows:
> mvn clean package
Submitting to Spark
To execute the program, we must use the spark-submit command to send our code to the Spark engine in the following way:
~yourSparkInstallation/spark-submit --class spark.Recommender --master local[*] --jars kivi- api-1.4-direct-client.jar,spark-lx-connector-1.4.jar movieRecommendation-1.0-SNAPSHOT.jar2> error.log
Where movieRecommendation-1.0-SNAPSHOT.jar is the jar generated in the previous step with the classes of your project. You must provide the paths to the kivi-api direct client jar and the LeanXcale Spark connector jar.
(Note that the main class in our project is spark.Recommender)
The error output has been redirected to error.log to avoid that the Spark log messages hiding the prompt to query the user for his ratings:
> Rate this movie: Thing, The (1982) from 0 (not seen) to 5 (Fabulous): 3 > Rate this movie: Citizen Kane (1941) from 0 (not seen) to 5 (Fabulous): 4 > Rate this movie: Taxi Driver (1976) from 0 (not seen) to 5 (Fabulous): 4
QUERYING THE RESULTS
Now that the personal recommendations are stored in the database, you can use your favorite SQL client with the LeanXcale JDBC driver to query the results.
lx> select title, rating from RESULT_RECOMMENDATIONS natural join MOVIES;
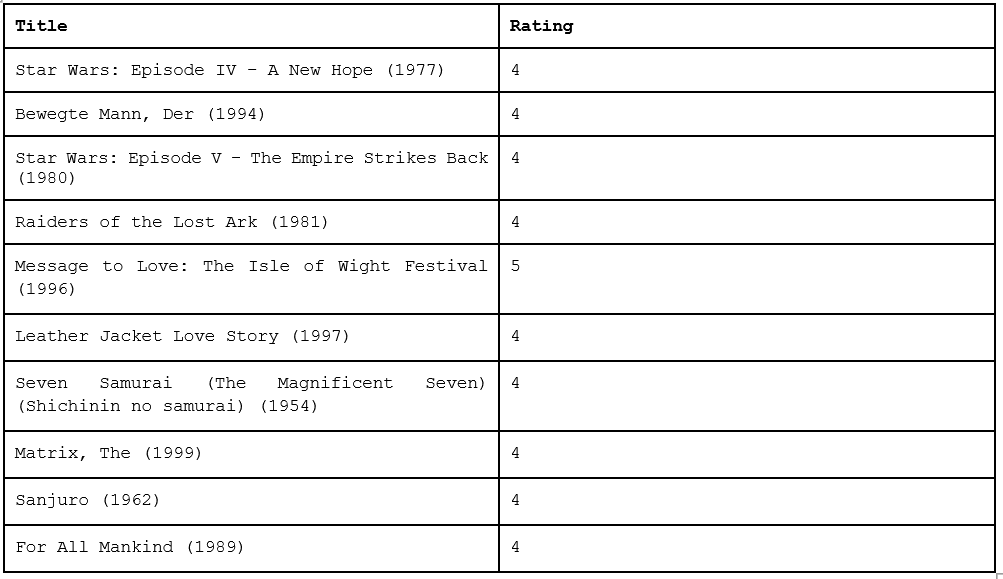
10 rows selected (0.068 seconds)
WRITTEN BY

Javier López Moratalla
Software Engineer at LeanXcale
After more than 15 years developing, designing and deploying enterprise software at companies like Hewlett Packard Enterprise or Gemalto, I’m now part of the LeanXcale team, researching and working on the next generation of databases.