

In the world of databases, most people have encountered some “hidden” processes executed in the background resulting in the spoiling of performance. Each database technology has its usual suspects. With Oracle, it is the RMAN process, and with PostgreSQL, troubles are clearly from the vacuum process. The vacuum process is a well-known drawback, and during recent years, I received many questions related to this process and how new databases managing these technical problems they try to overcome. This responsibility is a common headache for integration engineers, and the first target of any performance improvement task force executed over a system with database performance issues. But, honestly, we are all waiting for the day when this type of issue is solved, when a database does “what I tell it to do” instead of other stuff. This challenge has been one of my primary targets during the last two years developing LeanXcale. Within this context, multi-version concurrency control (MCC or MVCC) is a concurrency control method commonly used by modern database engines to provide snapshot isolation so the database can consistently provide concurrent read and write access. The approach is based on the creation of several versions for the same row with the trade-off being that the version management can reduce performance as the number of versions for the same row increases. Old versions should be deleted to avoid performance degradation, but this deletion process is particularly challenging for most database engines:
- In PostgreSQL, the vacuum process deletes obsolete tuples.
- In LeanXcale, innovative patent-pending technology is responsible for the task.
This post compares the impact of this deleting process in PostgreSQL and LeanXcale.
ENVIRONMENT
To test the impact of deleting old versions of data in the following three scenarios, a Yahoo! Cloud Serving Benchmark (YSCB) is executed, which is an open-source specification and program suite for evaluating the retrieval and maintenance capabilities of computer programs. YSCB is often used to compare the relative performance of database management systems.
The three selected scenarios include:
- PostgreSQL + manual vacuum.
- PostgreSQL + auto-vacuum.
- LeanXcale.
The test features the characteristics:
- A starting load of 400K registers.
- Both PostgreSQL scenarios execute 5 million updates.
- LeanXcale performs 50 million upserts.
- The same server is used with the specifications:

The different transaction loads (5M vs. 50M) is because LeanXcale is faster, so we attempt to create similar durations of the processing.
SCENARIO 1: POSTGRESQL WITH MANUAL FULL VACUUM
In this scenario, the auto-vacuum process is disabled, and the full vacuum is performed manually.
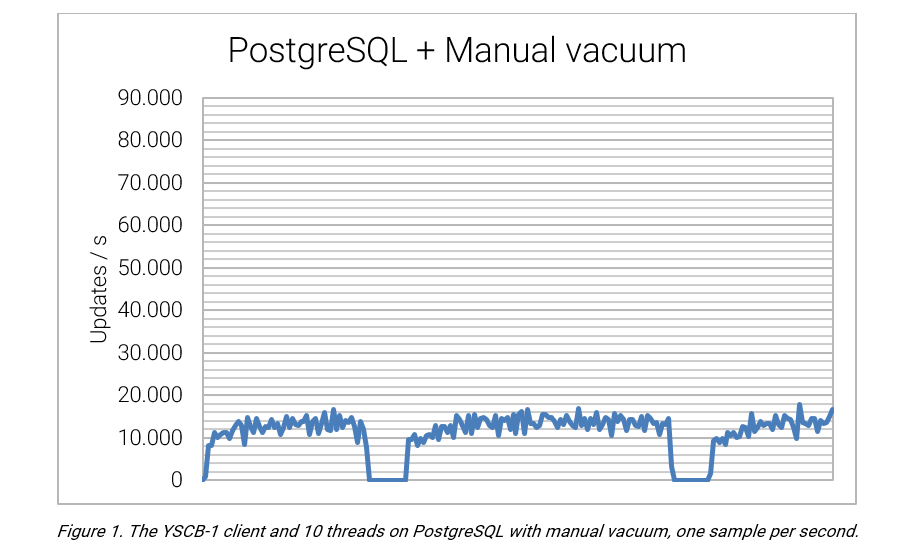
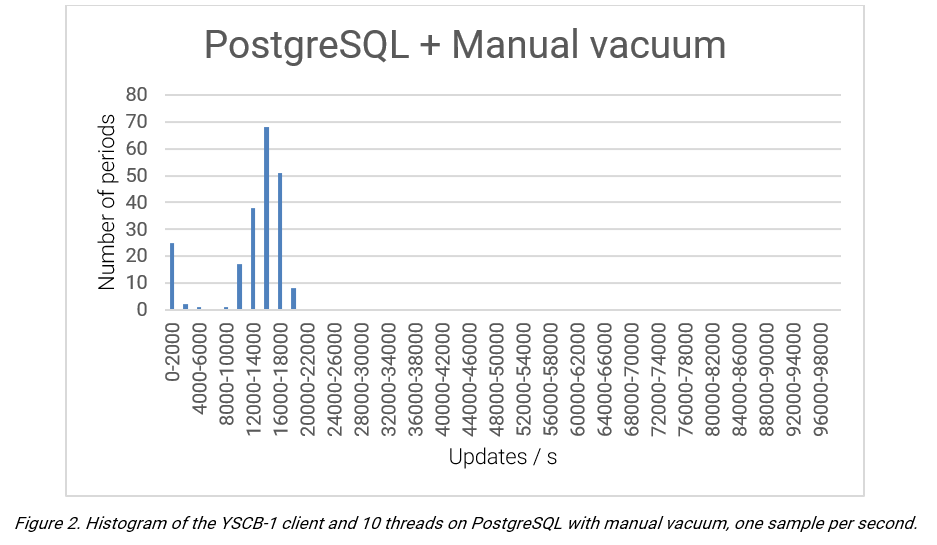
PostgresSQL provides an average rate of 11,193.75 updates per second, and the vacuum process is seen to provide a substantial impact on performance. When the vacuum is active, the number of updates per second reduces to zero. This negative impact is reflected by a standard deviation of 4,706.89.
SCENARIO 2: POSTGRESQL WITH ACTIVE AUTO-VACUUM
In this scenario, the auto-vacuum process is enabled. The performance appears erratic, with a significant difference between the local maximums and minimums.
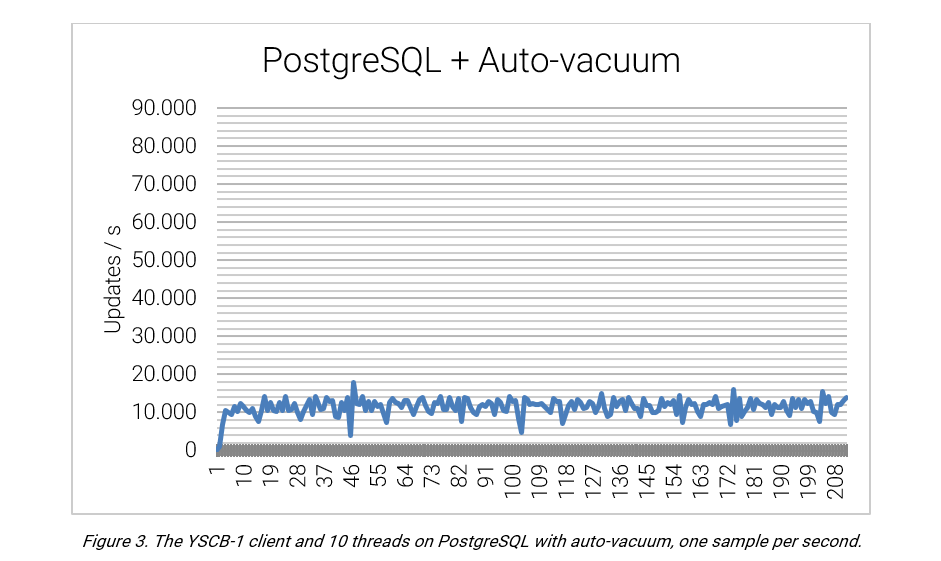
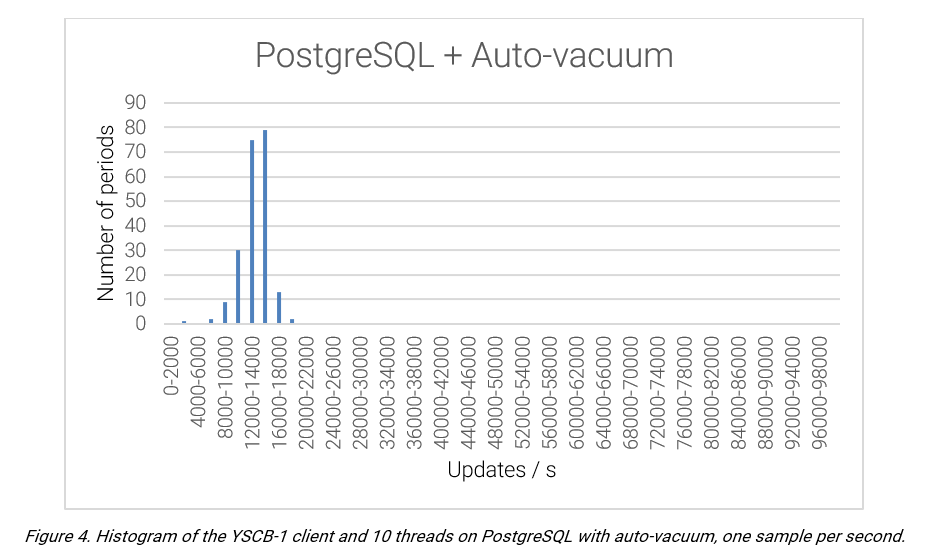
PostgreSQL provides an average performance of 11,574.62 updates per second, with a standard deviation of 1,920.57.
SCENARIO 3: LEANXCALE
Following the same scenario of the previous two cases, LeanXcale offers a more stable performance. LeanXcale leverages a direct API to KiVi, its relational key-value store engine, leading to a performance of a magnitude level higher (with an average 76,180 upserts/second) compared to the PostgreSQL scenarios.
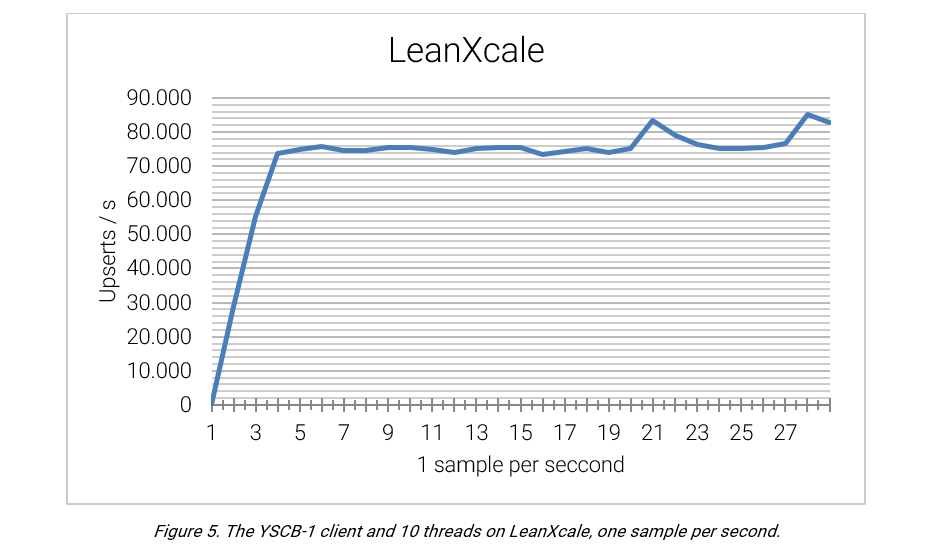
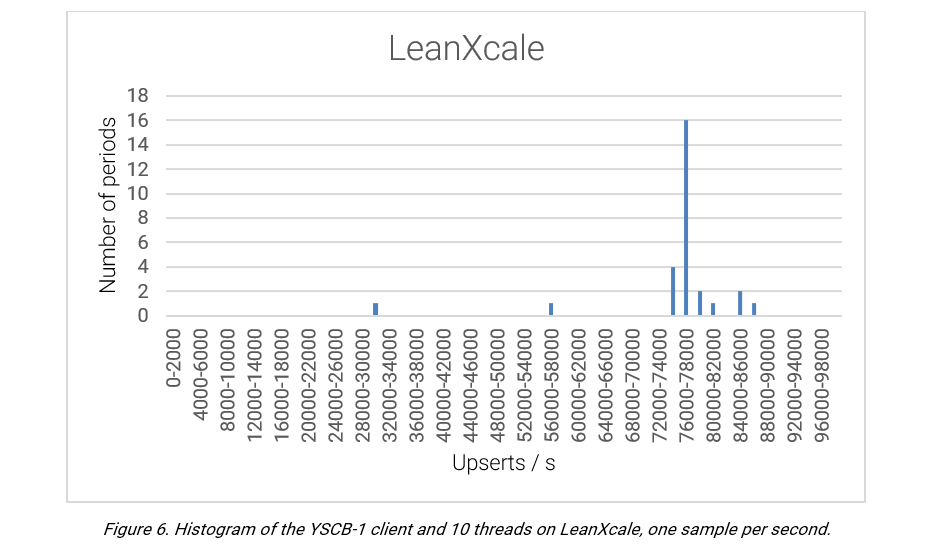
CONCLUSION
As we described above: The PostgreSQL vacuum process results in a strong and visible impact on performance. LeanXcale’s new MVCC uses an approach that is nearly costless and does not create issues for any update rate. This crucial difference is perfectly depicted by the different coefficients of variation of the solutions. LeanXcale is a magnitude order smaller than that of the PostgreSQL auto-vacuum.
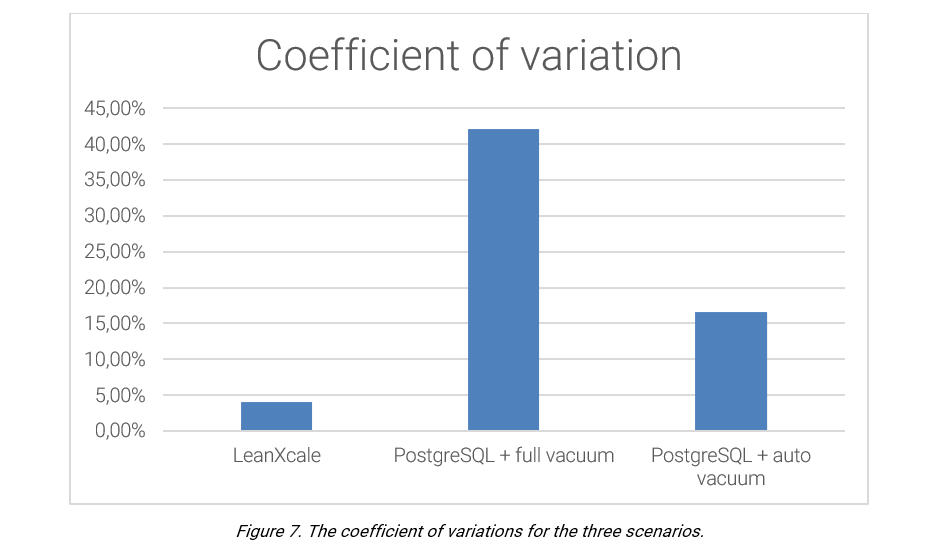
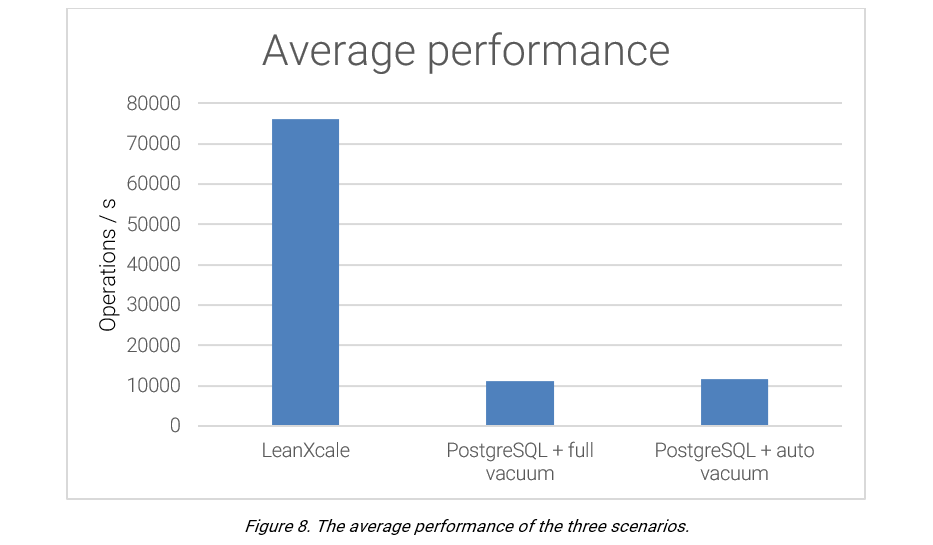
WRITTEN BY

José María Zaragoza Noguera
Software Engineer at LeanXcale
josemaria@leanxcale.com
https://www.linkedin.com/in/jos%C3%A9-m-zaragoza-noguera-82a559111/