

In this post, I show how to set up a local LeanXcale environment using Docker and Docker Compose for development purposes. This is very useful in development environments when we do not want to spend our time setting up complex, production-like environments and instead want to have a fully functional testing environment. Also, I show the benefit of scaling up the database with Docker Compose by distributing a table into two nodes and loading it in parallel.
All the code and configuration files used in this post can be downloaded from our git repository.
PREREQUISITES
The first prerequisite is to install Docker on a Linux machine where we will execute the LeanXcale database by following the instructions on their website. This post has been tested using Docker version 18.09.7 for client and server, and version 1.39 for the API version. This can be verified by running:
docker version
The output will be similar to:Client:
Version: 18.09.7
API version: 1.39
Go version: go1.10.4
Git commit: 2d0083d
Built: Fri Aug 16 14:19:38 2019
OS/Arch: linux/amd64
Experimental: false
Server:
Engine:
Version: 18.09.7
API version: 1.39 (minimum version 1.12)
Go version: go1.10.4
Git commit: 2d0083d
Built: Thu Aug 15 15:12:41 2019
OS/Arch: linux/amd64
Experimental: false
To obtain a LeanXcale Docker image, you may contact me following the information provided at the end of this article.
Also, you must install the LeanXcale SQLAlchemy Python driver, which can be downloaded from our website. Instructions on how to install is available in our post on sentiment analysis on tweets.
STANDALONE ENVIRONMENT
The most straightforward way of starting a LeanXcale database is in a Docker container. In this way, we spin up all LeanXcale components in the same Docker container and start the integration with our application without worrying about distribution and partitioning the data.
First, a little context for those not familiar with Docker images and containers. Docker containers are executable software packages that include everything necessary to run an application. So, using containerized applications avoids the process of installing required dependencies and fixing installation errors by making these applications platform-independent, as everything required is shipped in the container. The following figure illustrates the architecture of containerized applications.
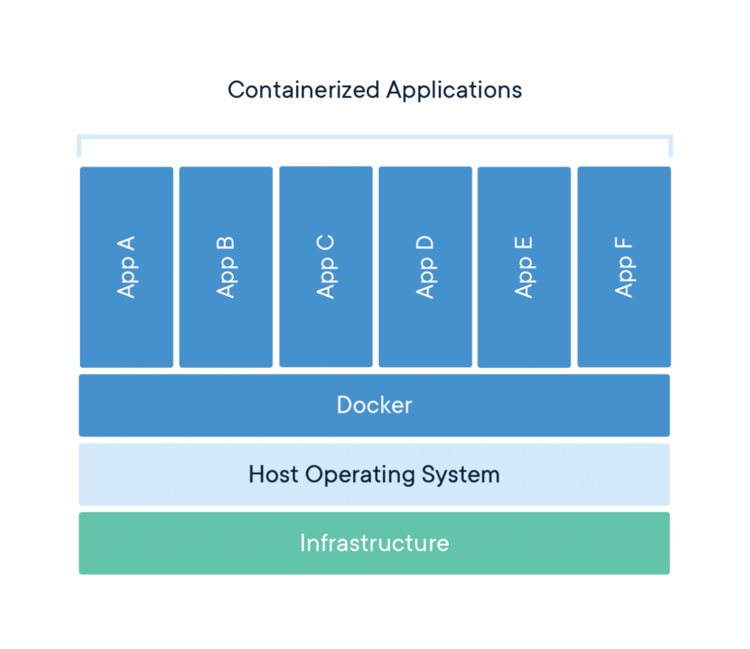
Fortunately, there is a LeanXcale docker image available and ready to go. From this image, a container is created at runtime, and a LeanXcale database is also initiated. To start a LeanXcale container, two things must be considered:
1) Network configuration. By default, Docker creates a bridge network, which is a good option for standalone containers that run on the same machine. Technically, a bridge can be a hardware or software piece that forwards traffic between two network segments. For our interest, we use this default network configuration forwarding port 1522 with the -p option, which is the port used by the query engine. So, this is the port we will use for our SQL, JDBC, and SQLAlchemy, for example.
2) The container must be run in the detached mode using the -d option.
So, to start the LeanXcale database in a container, we run:
docker run –name leanxcale_container -p 1522:1522 -d gitlab.lsdupm.ovh:5000/leanxcale:latest
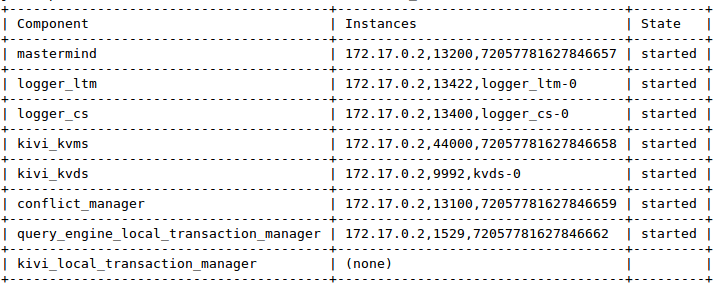
To check that LeanXcale started correctly, we execute an admin command to check the status inside our Docker using the Docker exec functionality. We should see an output like the following.
docker exec leanxcale_container /lx/LX-BIN/bin/lxConsole 3
EXAMPLE APPLICATION
Once LeanXcale is running, we execute an application using the SQLAlchemy driver. I provide a simple code snippet to test that everything is working. For the installation of the LeanXcale SQLAlchemy driver, please read this section in our Documentation.
The following simple Python code creates a connection using the autocommit option, creates a table with three fields and a primary key composed by the first field, inserts a record, and retrieves all elements from the created table.
import sqlalchemy
from sqlalchemy.ext.declarative import declarative_base
import random
if __name__ == "__main__":
db = sqlalchemy.create_engine('leanxcale://APP@localhost:1522/tpch')
conn = db.connect().execution_options(autocommit=True)
base = declarative_base()
conn.execute("CREATE TABLE TABLE_8 (f1 int, f2 VARCHAR, f3 int, PRIMARY KEY (f1))")
conn.execute("INSERT INTO TABLE_8 (f1,f2,f3) values(" + str(random.randint(5, 1000000)) + ",'insert',3)")
result = conn.execute("select * from TABLE_8")
for row in result:
print("Tuple: " + str(row))
conn.close()
DISTRIBUTED ENVIRONMENT
Even though this article aims to provide a solution for setting up a development environment as quickly as possible, it may still be interesting when developing applications to have a distributed environment. Nevertheless, this would only be for development purposes. I will publish a separate post with details on how to set up a distributed production environment using Kubernetes, but in the meantime you can read our documentation about it.
To configure this distributed environment, we use Docker Compose. By using a configuration file, we specify the components that should be started and the number of instances per component. So, the process creates a distributed environment formed by containers inside the same host machine.
In the git repository associated with this post, you will find the YAML file with the configuration, which specifies the different services that are spun up with different internal configurations. Please do not change any of these configuration parameters, such as the environment variables passed to each container. All services can be scaled up except from the meta_node.
If we want to start LeanXcale in a distributed mode using Docker Compose, with the YAML file previously mentioned, we must execute the following command:
docker-compose up –scale kvds_node=2
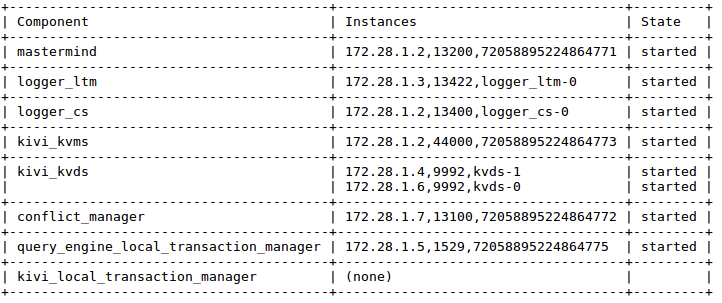
This will start LeanXcale with two datastore nodes, and if we check the status of the deployment, we execute in the meta node the admin command used previously:
docker exec lx-image_meta_node_1 /lx/LX-BIN/bin/lxConsole 3
NOTE: The name of the container may be different from the one in this example, so please use the name of your meta container. You can list the running containers by running docker ps.
You should see an output like the following where two instances for the datastore exist.
DISTRIBUTED EXAMPLE APPLICATION
We could run the same code example from the standalone deployment, but we would then not take advantage of our distributed environment. Instead, I show how we split a table into our two datastore nodes and make a load using two threads in parallel with each by attacking a different partition.
In this distributed environment, different components run in different docker containers, so we need to know the endpoint for the Docker container running our query engine. We inspect the node named dockerlx_meta_node_1_9dbbd1576a5f by running:
docker inspect dockerlx_meta_node_1_9dbbd1576a5f
Once we identify the IP of the query engine, we use the following simple SQLAlchemy code to create a table:
import sqlalchemy
from sqlalchemy.ext.declarative import declarative_base
import random
if __name__ == "__main__":
db = sqlalchemy.create_engine('leanxcale://APP@172.28.1.5:1522/tpch')
conn = db.connect().execution_options(autocommit=True)
base = declarative_base()
conn.execute("CREATE TABLE TABLE_8 (f1 int, f2 VARCHAR, f3 int, PRIMARY KEY (f1))")
conn.close()
Once the table is created, we can observe in which of the two datastores it is located.
docker exec dockerlx_meta_node_1_9dbbd1576a5f /lx/LX-BIN/exe/kvcon -a 172.28.1.2!44000 list tpch-APP-TABLE_8
Here, we see that it is located in datastore 1.
tbl tpch-APP-TABLE_8 [1k+0c/3] avgtsz 56
0k:0u i F1
1k:1u s F2
2k:2u i F3
no.perms
reg addr kvds-1 id 4222124650659842
minv: mint
maxv: maxt
Now, we split across the two available datastores by specifying the table and key that will serve as the split point. In our test, the key is formed by one integer field, so we insert 1000 records and set the split point at 500.
docker exec dockerlx_meta_node_1_9dbbd1576a5f /lx/LX-BIN/bin/lxConsole splitTable tpch-APP-TABLE_8 500 kvds-0
If we inspect our table again, then we see that the table is now distributed in both datastores, and records with keys up to 500 are stored in datastore 1, and from 500 to the maximum value in datastore 2.
tbl tpch-APP-TABLE_8 [1k+0c/3] avgtsz 56
0k:0u i F1
1k:1u s F2
2k:2u i F3
no.perms
reg addr kvds-1 id 4785074604081154
minv: mint
maxv: t0 - 500
reg addr kvds-0 id 3659174697238530
minv: t0 - 500
maxv: maxt
Next, we run a Python script that uses threads to insert records into both regions. So, we insert data in parallel, thereby doubling the performance and reducing the load time by a factor of two! Using SQL is not the optimal way of performing such massive load phases. So, for this purpose, LeanXcale offers a key-value interface. In this post, you can see a benchmark using LeanXcale’s key-value interface against DynamoDB.
The following Python script uses threads to create a session, insert 500 records to each in one partition, and commits the transaction. If an error occurs during the session, then the transaction is aborted.
from sqlalchemy import *
from sqlalchemy.orm import *
from threading import Thread
def worker(kmin, kmax):
print('Worker:', kmin)
param = []
for i in range(kmin, kmax):
param.append({'f1': i, 'f2': 'string1', 'f3': 0})
db = create_engine('leanxcale://APP@172.28.1.7:1522/tpch')
Session = sessionmaker(autocommit=False)
Session.configure(bind=db)
sess = Session()
meta = MetaData(bind=db)
meta.reflect(db)
table = Table('TABLE_8', meta,
Column('f1', Integer, primary_key=True),
Column('f2', String ),
Column('f3', Integer), extend_existing=True)
try:
sess.execute(table.insert(),param)
sess.commit()
print("Commited")
except Exception as e:
print(e)
sess.rollback()
print("Rollback")
sess.close()
if __name__ == "__main__":
p1 = Thread(target=worker, args=(0, 500,))
p2 = Thread(target=worker, args=(501, 1001,))
p1.start()
p2.start()
CONCLUSION
In this post, we demonstrated how to deploy a LeanXcale database for a development environment using Docker containers. We accomplished this by starting the database in a single container as well as a distributed one by using Docker Compose to scale up the components needed. Finally, we showed how to take advantage of data partitions across different LeanXcale datastores by splitting a table into two datastore nodes and use both to load a table resulting in half the loading time typically required when incorporating one thread for loading.
If you are interested in executing the details outlined in this post and want to obtain the LeanXcale Docker image, or, while experimenting with this process you encountered issues or want to solve some doubts, then do not hesitate to contact me using the information below.
Happy coding!
WRITTEN BY

Jesús Manuel Gallego Romero
Software Engineer at LeanXcale
jesus.gallego@leanxcale.com
https://www.linkedin.com/in/jes%C3%BAs-manuel-gallego-romero-68a430134/