
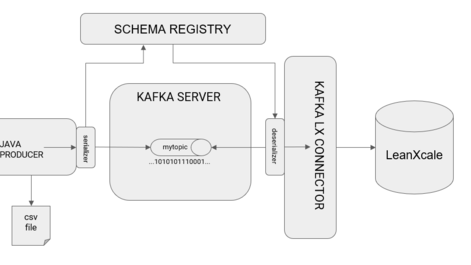
As promised, here is the continuation of the post about the Kafka connector for LeanXcale. Let’s see how to execute it!
Execution
To implement this example, the Kafka suite must first be downloaded. Confluent is an open source distribution by Kafka, founded by the original creators of Kafka, and offers a set of tools and utilities related to the complete management of the server. Specifically, this package includes Zookeeper, Kafka Server, Schema Registry, and Kafka Connect, which covers all the components needed to execute.
The Kafka suite can be downloaded from http://packages.confluent.io/archive/5.4/confluent-community-5.4.1-2.12.tar.gz
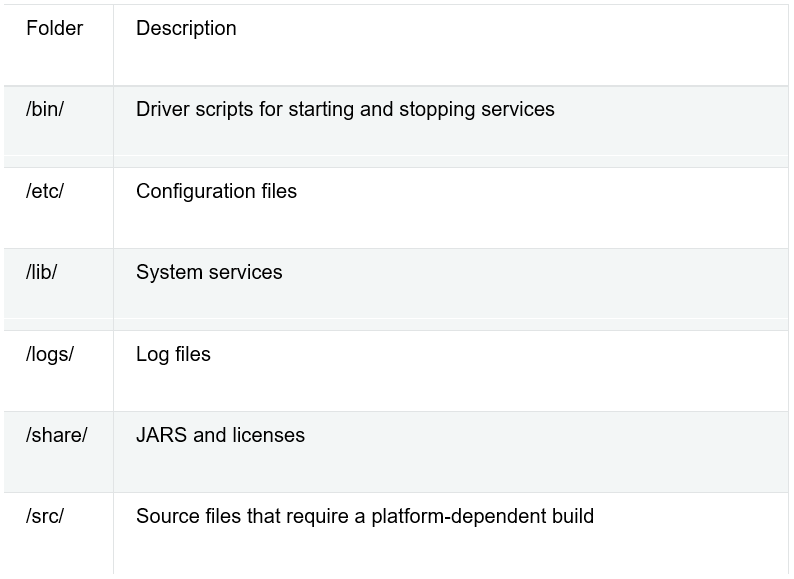
We decompress the file on a local PC, and the following directory structure should remain:
Configuration
Please note the Kafka configuration described in this post is the default and simplest one, with just one broker.
ZOOKEPER
Navigate to the confluent-5.4.1/etc/kafka directory and open the “zookeeper.properties” file. Leave the default configuration in place, and make sure the file contains:
clientPort=2181
This is the port to listen for client connections.
KAFKA SERVER
Navigate to the confluent-5.4.1/etc/kafka directory and open the “server.properties” file. Leave the default configuration, and make sure the file contains:
broker.id=0
listeners=PLAINTEXT://:9092
With these lines, the broker’s identifier is defined (i.e., the server, where this example includes only one, but more servers could act in a cluster) as well as the port where Kafka listens (i.e., 9092).
To run the client from a different machine from the kafka server, we must set up a reachable server ip (localhost/0.0.0.0 not valid for remote connections)
listeners=PLAINTEXT://ip_kfk_srvr:9092
SCHEMA REGISTRY
Navigate to the confluent-5.4.1/etc/schema-registry directory and open the schema-registry.properties file. Leave the default configuration, and make sure the file contains:
listeners=http://0.0.0.0:8081
This line defines the IP address and port where the schema registry listens, and the default value is 8081.
KAFKA CONNECT
Navigate to the confluent-5.4.1/etc/kafka directory and open the connect-standalone.properties file. The following lines must exist:
bootstrap.servers=0.0.0.0:9092
max.poll.records=500
plugin.path=/usr/local/share/kafka/plugins
The first line defines the IP address and port on which the Kafka server resides. The next line defines the maximum number of records to be requested from the Kafka topic on each call. The last line defines the Kafka Connect plugin directory into which the Kafka connector for LeanXcale is copied.
KAFKA CONNECTOR FOR LEANXCALE
Next, download the Kafka Connector from our website.
The connector is contained in a tar.gz, so it must be unpacked into the directory indicated as plugin.path in the Kafka connect configuration.
Once extracted, the connector is configured. Navigate to the directory confluent-5.4.1/etc/kafka and create a new file named “connect-lx-sink.properties” with the following configuration added to the file:
name=local-lx-sink
connector.class=com.leanxcale.connector.kafka.LXSinkConnector
tasks.max=1
topics=mytopic
connection.properties=lx://ip_bd_leanxcale:9876/mytestdatabase@app
connection.properties=lx://ip_bd_leanxcale:9876/mytestdatabase@app;cert/path/to/certificate/file.kcf
auto.create=true
batch.size=500
connection.check.timeout=20
key.converter=io.confluent.connect.avro.AvroConverter
key.converter.schema.registry.url=http://localhost:8081
value.converter=io.confluent.connect.avro.AvroConverter
value.converter.schema.registry.url=http://localhost:8081
sink.connection.mode=kivi
sink.transactional=false
table.name.format=${topic}
pk.mode=record_key
pk.fields=id
fields.whitelist=trip_duration_secs,start_time,stop_time,start_station_id,star
t_station_name, \
start_station_latitude,start_station_longitude,end_station_id,end_station_name
,end_station_latitude, \
end_station_longitude,bike_id,user_type,user_birth_year,user_gender
The main configuration lines represent the following:
- name: Name of the connector.
- connector.class: Java class executed when the connector is lifted.
- tasks.max: Number of threads that read from the topic.
- topics: Name of the topic to read from.
- connection.properties: the connection url along with its corresponding properties to connect to the datastore. The parameter ip_bd_leanxcale must match the one provided by the LeanXcale instance. To run the client from a different machine from the kafka server, we must set up a reachable ip_bd_leanxcale (localhost/0.0.0.0 not valid for remote connections). Moreover, we need to provide the database logical name to connect, which is ‘mytestdatabase’ in our example, and the name of the user that will open the connection, which in our example is ‘app’. In case it is required to use secure connections to LeanXcale, the file path of the certificate needs to be provided as well, as the commented attribute demonstrates.
- auto.create: If true, the connector should create the target table if not found.
- batch.size: Maximum number of records to be sent in a single commit to LeanXcale.
- connection.check.timeout: Active connection checkout time.
- key.converter: Serializer of the registry key on the Kafka server, which is Avro for this example.
- key.converter.schema.registry.url: URL where the schema registry is listening from and contains the configuration file.
- value.converter: Serializer of the registry value in the Kafka server, which is also Avro, for this case.
- value.converter.schema.registry.url: URL where you are listening to the schema registry. It is the one that contains your configuration file.
- sink.connection.mode: LeanXcale connection mode value that defines the connection through the NoSQL interface.
- sink.transactional: Whether the load on LeanXcale is going to be executed with ACID transactions or not. The false value means the ACID capabilities are not going to be complied. This scenario potentially increases the insertion performance, and is indicated in case of big initial loads without consistency requirements over operational environments. For more information about LeanXcale ACID transactions, please refer to our documentation.
- table.name.format: Name of the destination table where ${topic} represents what it will be called as the topic. In this example, the target table is called “mytopic”.
- pk_mode: Indicates the primary key mode of the target table where record_key means that it will use the key field value of the record stored in Kafka as the primary key in the target table.
- pk_fields: Fields of the pk among what arrives in the key field. In our case, only one exists in the “id” field.
- fields.whitelist: List of the fields in the record to be columns in the target table. If all fields are included, then all will become columns. However, those that should not be created in the table can be removed.
Start
After everything above is installed and configured, the processes are initialized.
ZOOKEEPER
The first step is to start the process manager, Zookeeper. Without this tool, no other component will start because they rely on this to find one another. Navigate to the confluent-5.4.1/bin directory and run:
nohup ./zookeeper-server-start ../etc/kafka/zookeeper.properties > nohup_zk.out &
Previewing the newly generated log with the command tail -100f nohup_zk.out, the last few lines will include something like:
[2020-03-31 09:07:55,343] INFO Using org.apache.zookeeper.server.NIOServerCnxnFactory as server connection factory (org.apache.zookeeper.server.ServerCnxnFactory) [2020-03-31 09:07:55,345] INFO Configuring NIO connection handler with 10s sessionless connection timeout, 2 selector thread(s), 24 worker threads, and 64 kB direct buffers(org.apache.zookeeper.server.NIOServerCnxnFactory) [2020-03-31 09:07:55,347] INFO binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.NIOServerCnxnFactory) [2020-03-31 09:07:55,357] INFO zookeeper.snapshotSizeFactor = 0.33 (org.apache.zookeeper.server.ZKDatabase) [2020-03-31 09:07:55,359] INFO Snapshotting: 0x0 to /tmp/zookeeper/version- 2/snapshot.0 (org.apache.zookeeper.server.persistence.FileTxnSnapLog) [2020-03-31 09:07:55,361] INFO Snapshotting: 0x0 to /tmp/zookeeper/version- 2/snapshot.0 (org.apache.zookeeper.server.persistence.FileTxnSnapLog) [2020-03-31 09:07:55,372] INFO Using checkIntervalMs=60000 maxPerMinute=10000 (org.apache.zookeeper.server.ContainerManager)
To exit the tail output, press Ctrl+c.
KAFKA SERVER
After Zookeeper is started, the Kafka server is initiated from the confluent-5.4.1/bin directory with the command:
nohup ./kafka-server-start ../etc/kafka/server.properties > nohup_kafka_server.out &
By tailing the log file with tail -100f nohup_kafka_server.out, something like the following will display:
[2020-03-31 09:11:44,434] INFO Kafka version: 5.4.1-ccs (org.apache.kafka.common.utils.AppInfoParser) [2020-03-31 09:11:44,435] INFO Kafka commitId: 1c8f62230319e789 (org.apache.kafka.common.utils.AppInfoParser) [2020-03-31 09:11:44,435] INFO Kafka startTimeMs: 1585638704434 (org.apache.kafka.common.utils.AppInfoParser) [2020-03-31 09:11:44,455] INFO [Producer clientId=producer-1] Cluster ID: _KCRiquMRVm85wsVsE3ATQ (org.apache.kafka.clients.Metadata) [2020-03-31 09:11:44,497] INFO [Producer clientId=producer-1] Closing the Kafka producer with timeoutMillis = 9223372036854775807 ms. (org.apache.kafka.clients.producer.KafkaProducer) [2020-03-31 09:11:44,499] INFO Successfully submitted metrics to Kafka topic __confluent.support.metrics (io.confluent.support.metrics.submitters.KafkaSubmitter) [2020-03-31 09:11:45,815] INFO Successfully submitted metrics to Confluent via secure endpoint (io.confluent.support.metrics.submitters.ConfluentSubmitter)
So, the Kafka server is now up and running.
SCHEMA REGISTRY
After the Kafka server starts, the registry schema is initiated so that Avro registers the schema of the records it sends. From confluent-5.4.1/bin, launch the command:
nohup ./schema-registry-start ../etc/schema-registry/schema-registry.properties > nohup_schema_registry_server.out &
Check the status with tail -100f nohup_schema_registry_server.out:
[2020-03-31 09:14:39,120] INFO HV000001: Hibernate Validator 6.0.11.Final
(org.hibernate.validator.internal.util.Version:21)
[2020-03-31 09:14:39,283] INFO JVM Runtime does not support Modules
(org.eclipse.jetty.util.TypeUtil:201)
[2020-03-31 09:14:39,283] INFO Started o.e.j.s.ServletContextHandler@66b7550d{/,null,AVAILABLE}
(org.eclipse.jetty.server.handler.ContextHandler:824)
[2020-03-31 09:14:39,294] INFO Started o.e.j.s.ServletContextHandler@2ccca26f{/ws,null,AVAILABLE}
(org.eclipse.jetty.server.handler.ContextHandler:824)
[2020-03-31 09:14:39,305] INFO Started
NetworkTrafficServerConnector@3e57cd70{HTTP/1.1,[http/1.1]}{0.0.0.0:8081}
(org.eclipse.jetty.server.AbstractConnector:293)
[2020-03-31 09:14:39,305] INFO Started @2420ms (org.eclipse.jetty.server.Server:399)
[2020-03-31 09:14:39,305] INFO Server started, listening for requests...
(io.confluent.kafka.schemaregistry.rest.SchemaRegistryMain:44)
So, the schema registry is now started.
KAFKA CONNECTOR FOR LEANXCALE
Finally, the Kafka connector for LeanXcale is initiated. After including the IP of the LeanXcale DB into the configuration file, as indicated in the configuration section above, execute the following command:
nohup ./connect-standalone ../etc/kafka/connect-standalone.properties ../etc/kafka/connect-lx-sink.properties > nohup_connect_lx.out &
Looking at the log:
[2020-03-31 09:19:49,235] INFO [Consumer clientId=connector-consumer-local-
jdbc-sink-0, groupId=connect-local-jdbc-sink] (Re-)joining group
(org.apache.kafka.clients.consumer.internals.AbstractCoordinator:533)
[2020-03-31 09:19:49,285] INFO [Consumer clientId=connector-consumer-local-
jdbc-sink-0, groupId=connect-local-jdbc-sink] (Re-)joining group
(org.apache.kafka.clients.consumer.internals.AbstractCoordinator:533)
[2020-03-31 09:19:49,305] INFO [Consumer clientId=connector-consumer-local-
jdbc-sink-0, groupId=connect-local-jdbc-sink] Finished assignment for group at
generation 1: {connector-consumer-local-jdbc-sink-0-ae0d5fda-a1f2-4a10-95ca-
23bd3246481c=Assignment(partitions=[mytopic-0])}
(org.apache.kafka.clients.consumer.internals.ConsumerCoordinator:585)
[2020-03-31 09:19:49,321] INFO [Consumer clientId=connector-consumer-local-
jdbc-sink-0, groupId=connect-local-jdbc-sink] Successfully joined group with generation 1
(org.apache.kafka.clients.consumer.internals.AbstractCoordinator:484)
[2020-03-31 09:19:49,324] INFO [Consumer clientId=connector-consumer-local-
jdbc-sink-0, groupId=connect-local-jdbc-sink] Adding newly assigned
partitions: mytopic-0
(org.apache.kafka.clients.consumer.internals.ConsumerCoordinator:267)
[2020-03-31 09:19:49,337] INFO [Consumer clientId=connector-consumer-local-
jdbc-sink-0, groupId=connect-local-jdbc-sink] Found no committed offset for
partition mytopic-0
(org.apache.kafka.clients.consumer.internals.ConsumerCoordinator:1241)
[2020-03-31 09:19:49,343] INFO [Consumer clientId=connector-consumer-local-
jdbc-sink-0, groupId=connect-local-jdbc-sink] Resetting offset for
partition mytopic-0 to offset 0.
(org.apache.kafka.clients.consumer.internals.SubscriptionState:381)
Now, all the components are started and ready.
Execution
A Java program is provided that reads the January 2020 bike-sharing data from a CSV file and inserts it into the Kafka queue. This program is an executable Java jar file with the name kafkaAvroNYCBikesProducer-1.0-SNAPSHOT-jar-with-dependencies.jar.
The Java code of the executable may be previewed here.
The code from above is fully commented and should be reviewed and understood first. For a general description, the code performs the following:
- Create the configuration of a producer and set the IP and port of the Kafka server. Avro is set as the serializer of the key and value of the records. Remember that the data contained in the Kafka topics are neither text nor objects or readable entities but key-value structures with values that are strings of bytes, so using serializers apply meaning to the data.
- Create a KafkaProducer with the above configuration.
- Create a schema for the key as a single field containing an auto-incremented ID value.
- Create a schema for the values from all the columns of the CSV file.
- Open and read the CSV file.
- From each row of the CSV file, create a record with the key and value defined in the previous schemas and read these values from the CSV file.
- Send the record to the Kafka server.
To execute, run the command:
java -jar kafkaAvroNYCBikesProducer-1.0-SNAPSHOT-jar-with-dependencies.jar
After the execution is launched, review the log of the Kafka connector for LeanXcale to see the following:
[2020-03-31 09:33:43,342] INFO Flushing records in writer for table com.leanxcale.connector.kafka.utils.metadata.TableId@a25226fa with name mytopic (com.leanxcale.connector.kafka.sink.impl.LXWriterImpl:54) **[2020-03-31 09:33:43,342] INFO Connecting to database for the first time... (com.leanxcale.connector.kafka.connection.impl.AbstractLXConnectionProvider:33) [2020-03-31 09:33:43,342] INFO Attempting to open connection (com.leanxcale.connector.kafka.connection.impl.AbstractLXConnectionProvider:60) Conn: loading libkv from libkv.so Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /tmp/libkv41983156673418059.so which might have disabled stack guard. The VM will try to fix the stack guard now. It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'. [2020-03-31 09:33:43,408] INFO Registering builder com.leanxcale.kivi.database.constraint.GeohashConstraintBuilder@355d0da4 for prefix GH (com.leanxcale.kivi.database.impl.TableMetadataSerializer:34) [2020-03-31 09:33:43,409] INFO Registering builder com.leanxcale.kivi.database.constraint.DeltaConstraintBuilder@4d19b0e7 for prefix DEL (com.leanxcale.kivi.database.impl.TableMetadataSerializer:34) [2020-03-31 09:33:43,410] INFO Registering builder com.leanxcale.kivi.database.constraint.UUIDConstraintBuilder@6033bc5c for prefix UUID (com.leanxcale.kivi.database.impl.TableMetadataSerializer:34) [2020-03-31 09:33:43,411] INFO Registering builder com.leanxcale.kivi.database.constraint.ReflectStorableConstraint@3ff680bd for prefix ABS (com.leanxcale.kivi.database.impl.TableMetadataSerializer:34) 09:33:43 1585640023972632000 kv.Conn[26954]: *** no.auth = 1 09:33:43 1585640023972664000 kv.Conn[26954]: *** no.crypt = 2 09:33:43 1585640023972669000 kv.Conn[26954]: *** no.chkfull = 1 09:33:43 1585640023972673000 kv.Conn[26954]: *** no.flushctlout = 1 09:33:43 1585640023972677000 kv.Conn[26954]: *** no.npjit = 1 09:33:43 1585640023972681000 kv.Conn[26954]: *** no.tplfrag = 1 09:33:43 1585640023972684000 kv.Conn[26954]: *** no.dictsort = 1 [2020-03-31 09:33:44,346] INFO New session created: 1 (com.leanxcale.connector.kafka.connection.impl.LXKiviConnectionProvider:46) **[2020-03-31 09:33:44,346] INFO Table com.leanxcale.connector.kafka.utils.metadata.TableId@a25226fa is not registered for the connector. Checking db... (com.leanxcale.connector.kafka.sink.impl.LXWriterImpl:60) **[2020-03-31 09:33:44,347] INFO Table mytopic not found. Creating it (com.leanxcale.connector.kafka.sink.impl.LXWriterImpl:62) [2020-03-31 09:33:44,453] INFO Commited session: 1 (com.leanxcale.connector.kafka.connection.impl.LXKiviConnectionProvider:78) [2020-03-31 09:33:44,453] INFO Registering table mytopic in connector (com.leanxcale.connector.kafka.sink.impl.LXWriterImpl:71) **[2020-03-31 09:33:44,453] INFO Writing 1 records (com.leanxcale.connector.kafka.sink.impl.LXWriterImpl:84) [2020-03-31 09:33:44,817] INFO Commited session: 1 (com.leanxcale.connector.kafka.connection.impl.LXKiviConnectionProvider:78) [2020-03-31 09:33:44,821] INFO Flushing records in writer for table com.leanxcale.connector.kafka.utils.metadata.TableId@a25226fa with name mytopic (com.leanxcale.connector.kafka.sink.impl.LXWriterImpl:54) [2020-03-31 09:33:44,821] INFO Connecting to database... (com.leanxcale.connector.kafka.connection.impl.AbstractLXConnectionProvider:36) [2020-03-31 09:33:44,821] INFO Attempting to open connection (com.leanxcale.connector.kafka.connection.impl.AbstractLXConnectionProvider:60) [2020-03-31 09:33:44,821] INFO New session created: 2 (com.leanxcale.connector.kafka.connection.impl.LXKiviConnectionProvider:46) **[2020-03-31 09:33:44,821] INFO Table mytopic is already registered for the connector (com.leanxcale.connector.kafka.sink.impl.LXWriterImpl:75) **[2020-03-31 09:33:44,821] INFO Writing 4 records (com.leanxcale.connector.kafka.sink.impl.LXWriterImpl:84) [2020-03-31 09:33:45,004] INFO Commited session: 2 (com.leanxcale.connector.kafka.connection.impl.LXKiviConnectionProvider:78) [2020-03-31 09:33:45,080] INFO Flushing records in writer for table com.leanxcale.connector.kafka.utils.metadata.TableId@a25226fa with name mytopic (com.leanxcale.connector.kafka.sink.impl.LXWriterImpl:54) [2020-03-31 09:33:45,080] INFO Connecting to database... (com.leanxcale.connector.kafka.connection.impl.AbstractLXConnectionProvider:36) [2020-03-31 09:33:45,080] INFO Attempting to open connection (com.leanxcale.connector.kafka.connection.impl.AbstractLXConnectionProvider:60) [2020-03-31 09:33:45,080] INFO New session created: 3 (com.leanxcale.connector.kafka.connection.impl.LXKiviConnectionProvider:46) [2020-03-31 09:33:45,080] INFO Table mytopic is already registered for the connector (com.leanxcale.connector.kafka.sink.impl.LXWriterImpl:75) **[2020-03-31 09:33:45,080] INFO Writing 500 records (com.leanxcale.connector.kafka.sink.impl.LXWriterImpl:84) [2020-03-31 09:33:45,563] INFO Commited session: 3 (com.leanxcale.connector.kafka.connection.impl.LXKiviConnectionProvider:78) [2020-03-31 09:33:45,603] INFO Flushing records in writer for table com.leanxcale.connector.kafka.utils.metadata.TableId@a25226fa with name mytopic (com.leanxcale.connector.kafka.sink.impl.LXWriterImpl:54) [2020-03-31 09:33:45,604] INFO Connecting to database... (com.leanxcale.connector.kafka.connection.impl.AbstractLXConnectionProvider:36) [2020-03-31 09:33:45,604] INFO Attempting to open connection (com.leanxcale.connector.kafka.connection.impl.AbstractLXConnectionProvider:60) [2020-03-31 09:33:45,604] INFO New session created: 4 (com.leanxcale.connector.kafka.connection.impl.LXKiviConnectionProvider:46) [2020-03-31 09:33:45,604] INFO Table mytopic is already registered for the connector (com.leanxcale.connector.kafka.sink.impl.LXWriterImpl:75) **[2020-03-31 09:33:45,604] INFO Writing 500 records (com.leanxcale.connector.kafka.sink.impl.LXWriterImpl:84) [2020-03-31 09:33:45,910] INFO Commited session: 4 (com.leanxcale.connector.kafka.connection.impl.LXKiviConnectionProvider:78) [2020-03-31 09:33:45,924] INFO Flushing records in writer for table com.leanxcale.connector.kafka.utils.metadata.TableId@a25226fa with name mytopic (com.leanxcale.connector.kafka.sink.impl.LXWriterImpl:54) [2020-03-31 09:33:45,924] INFO Connecting to database... (com.leanxcale.connector.kafka.connection.impl.AbstractLXConnectionProvider:36) [2020-03-31 09:33:45,924] INFO Attempting to open connection (com.leanxcale.connector.kafka.connection.impl.AbstractLXConnectionProvider:60) [2020-03-31 09:33:45,924] INFO New session created: 5 (com.leanxcale.connector.kafka.connection.impl.LXKiviConnectionProvider:46) [2020-03-31 09:33:45,924] INFO Table mytopic is already registered for the connector (com.leanxcale.connector.kafka.sink.impl.LXWriterImpl:75) **[2020-03-31 09:33:45,924] INFO Writing 500 records (com.leanxcale.connector.kafka.sink.impl.LXWriterImpl:84)
Lines marked with ** at the beginning represent:
- The first connection to the DB.
- How the connector does not find the table previously existing in the DB, so creates it based on the schema defined in the producer code.
- How to insert the first record.
- How, for the subsequent four records, the connector finds the table it previously created.
- How to write these four records.
- How it collects all 500 records, which is the default number of records to collect from the Kafka server during each poll call, and inserts these into LeanXcale.
Additional information
Several additional commands for viewing and manipulating the topics on the Kafka server are described below, as well as the schemas registered in the schema registry.
The following command lists the topics created on the Kafka server:
./kafka-topics –list –bootstrap-server localhost:9092
The content of a topic is seen with the command:
./kafka-console-consumer –bootstrap-server localhost:9092 –topic mytopic –from-beginning
This command executes a consumer on the topic. Because Kafka stores an offset for each consumer, the execution of this consumer does not affect the reading of the records by the LeanXcale connector. In other words, what this consumer reads from the topic does not interfere with what the LeanXcale connector, a different consumer, reads from the same topic.
Considering what this command shows, because Kafka stores no semantic structure and only byte strings, strange characters may be seen in the output of the command.
To rerun the process from the beginning, delete the topic to remove all the previous information by first stopping the LeanXcale connector process, and then executing:
./kafka-topics –delete –bootstrap-server localhost:9092 –topic mytopic
Now, the connector process can be lifted and run again.
The registry schema includes an HTTP API to query its content of an organized list of the schemas it registered in the subjects. A subject refers to the name under which a schema is registered. In our case, and for Kafka, the subject is named “mytopic-key” for the schema created from the producer for the key, and the name “mytopic-value” for the value schema. The subjects can be seen by calling the URL http://:8081/subject or, with a curl command:
curl -X GET http://localhost:8081/subjects
In our case, this call returns:
[“mytopic-value”,”mytopic-key”]
Under these names, the schema registry stores versions of the schemas, which have the value:
curl -X GET http://localhost:8081/subjects/mytopic-value/versions
The following command returns the version numbers of the schemas it registered for the subject “mytopic-value”:

Only one schema is registered with the ID 1, and to see this scheme, execute the call:
curl -X GET http://localhost:8081/subjects/mytopic-value/versions/1
This returns the registered schema that coincides with what was previously sent from the producer.
{"subject":"mytopic-
value","version":1,"id":2,"schema":"{\"type\":\"record\",\"name\":\"myValue\",
\"namespace\":\"com.leanxcale\",\"fields\":[{\"name\":\"trip_duration_secs\",\
"type\":\"int\"},{\"name\":\"start_time\",\"type\":{\"type\":\"long\",\"logica
lType\":\"timestamp-
millis\"}},{\"name\":\"stop_time\",\"type\":{\"type\":\"long\",\"logicalType\"
:\"timestamp-
millis\"}},{\"name\":\"start_station_id\",\"type\":\"int\"},{\"name\":\"start_
station_name\",\"type\":\"string\"},{\"name\":\"start_station_latitude\",\"typ
e\":\"double\"},{\"name\":\"start_station_longitude\",\"type\":\"double\"},{\"
name\":\"end_station_id\",\"type\":\"int\"},{\"name\":\"end_station_name\",\"t
ype\":\"string\"},{\"name\":\"end_station_latitude\",\"type\":\"double\"},{\"n
ame\":\"end_station_longitude\",\"type\":\"double\"},{\"name\":\"bike_id\",\"t
ype\":\"int\"},{\"name\":\"user_type\",\"type\":\"string\"},{\"name\":\"user_b
irth_year\",\"type\":\"int\"},{\"name\":\"user_gender\",\"type\":\"int\"}]}"}
Conclusions
By using the Kafka sink connector for LeanXcale, a mechanism can be conveniently established to communicate with LeanXcale from a component of any operational or Big Data architecture via Kafka. The connector behaves similarly to the official JDBC connector for Kafka while using the more powerful LeanXcale non-SQL interface. In addition, due to the dual SQL and no-SQL interfaces available in LeanXcale, a very high-performance insertion can be maintained, while exploiting the data with any BI viewer that queries via SQL.
WRITTEN BY

Sandra Ebro Gómez
Software Engineer at LeanXcale
10 years working as a J2EE Architect in Hewlett-Packard and nearly 2 years working in EVO Finance and The Cocktail as a Solution Architect. Now part of LeanXcale team, trying to look for and develop the best usecases for high escalable databases.