
Motivation: Supporting 360º View of Monitored Systems at Any Scale
Monitoring applications must deal with systems of very different sizes; from a simple web server to several large data centers. Every device and aspect of the platform should be monitored individually to provide the highest level of granularity.
The bigger the scale of the monitored system, the higher the data rate that needs to be ingested, the bigger the number of KPIs that need to be computed and the larger the volume of historic data that needs to be queried in combination with the current data. This means that the underlying database of the monitoring system should be able to handle the load of the highest scale of the monitored systems.
If the underlying database is not scalable, the most common solution is sharding. In other words, to have several independent databases and each of them is dedicated to hold data about a fraction of the platform. This solution faces several issues:
- KPIs that aggregate data from different database instances cannot be computed in real-time. Alarms based on thresholds of these KPIs are not triggered or triggered late if a Manager of Managers (MoM) alternative is used.
- Events that are stored in different shards and have a common root-cause appear as independent events (data across shards cannot be queried with SQL since each shard is an independent database manager with no visibility of the other shards).
- Mutual relationships between different database metrics are not considered, reducing forecast accuracy.
- Due to these limitations, deciding the metrics inventory management (what metrics of a device are persisted) becomes more and more complex.
What is really needed and valuable is the availability of a global 360° view for a monitored system that is independent of its scale. This goal can be achieved by using a single global database. However, to address the problem at any scale, the database needs to be horizontally scalable. When a particular deployment of the database cannot handle more data, one just needs to add a new node to be able to handle more data.
Problem: SQL Databases Do not Scale, NoSQL lacks SQL queries
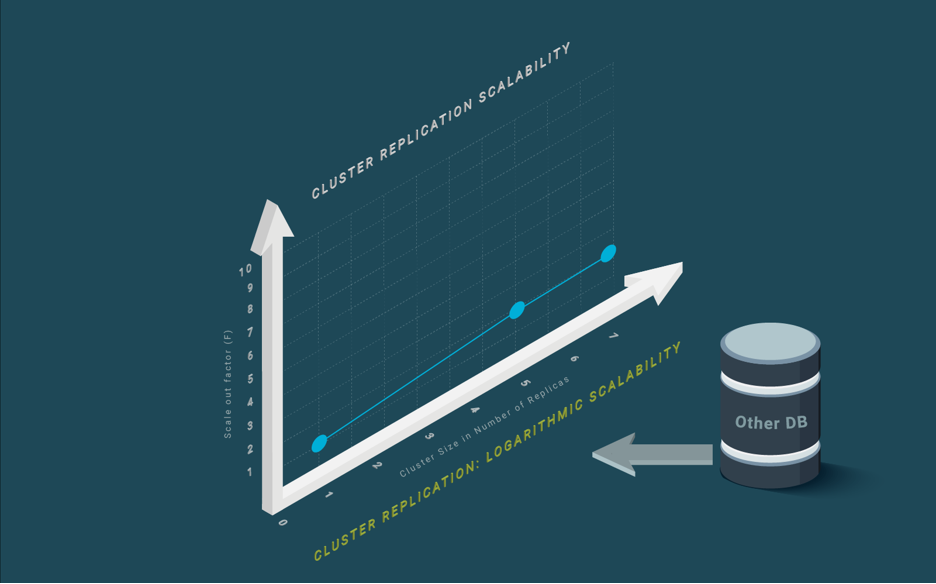
A main issue is that SQL operational databases today are either centralized or, if they are distributed databases, scale out logarithmically (see our blog post on Cluster Replication), resulting in very inefficient and quite limited scaling. There are a good number of NoSQL technologies that can scale and some of them can scale out linearly, typically, some distributed key-value data stores. However, NoSQL data stores are not efficient at querying data.
This situation results in either going to NoSQL and having a lower performance when performing the queries over the NoSQL data or creating a complex architecture, such as lambda architecture, that combines SQL and NoSQL. Both approaches result in a high TCO due to the low efficiency or the higher cost of developing and maintaining the code.
Solution: LeanXcale Horizontal Linear Scalability
One differential key feature of LeanXcale is its horizontal linear scalability (see our blog post on Scalability). LeanXcale is a shared-nothing distributed database (see our blog post on Shared Nothing) that runs on commodity hardware, either on-premise or in the cloud. Figure 1 depicts the architecture of LeanXcale in terms of subsystems. At the bottom, there is LeanXcale’s own proprietary storage engine known as KiVi. KiVi is an ultra-efficient distributed storage engine (actually, a relational key-value data store).
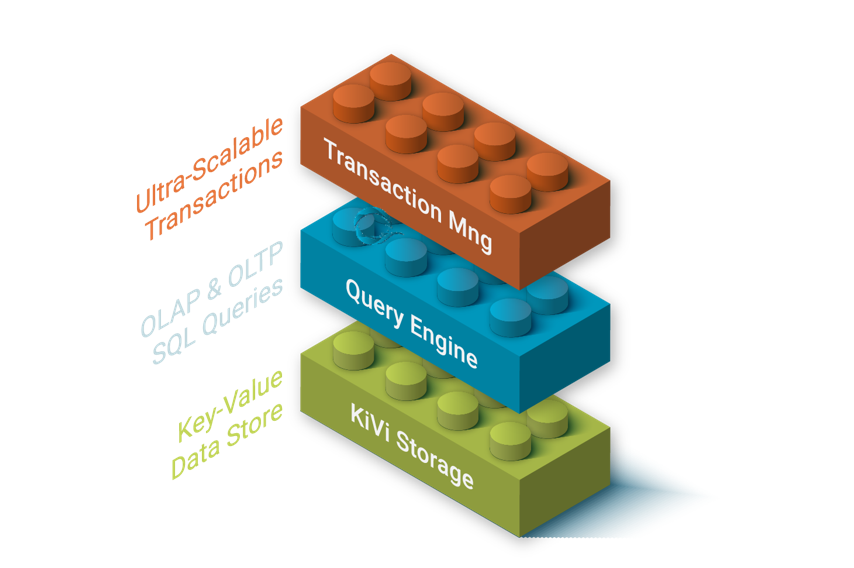
KiVi is itself a distributed relational key-value data store. In fact, LeanXcale relational tables can be accessed from both the SQL interface and the KiVi native NoSQL interface. This dual interface is extremely convenient because data can be efficiently ingested at very high rates with very little resources by using the native key-value interface. In fact, KiVi actually implements all SQL algebraic operators but joins. This means that, through its interface, it can process any queries with filtering, aggregation, grouping and sorting, without the overhead of SQL processing. KiVi is integrated with LeanXcale ultra-scalable transactional manager, which means that it is a fully ACID, key-value data store.
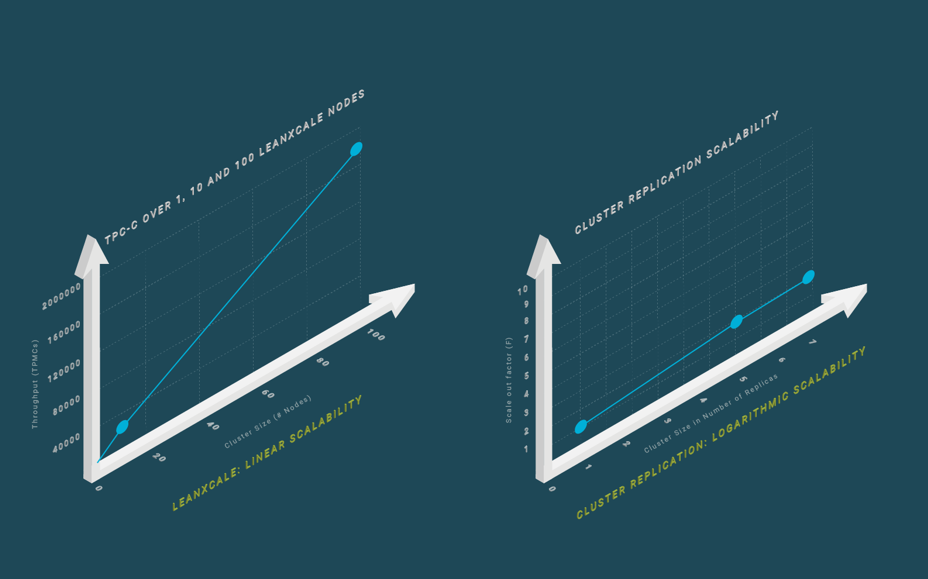
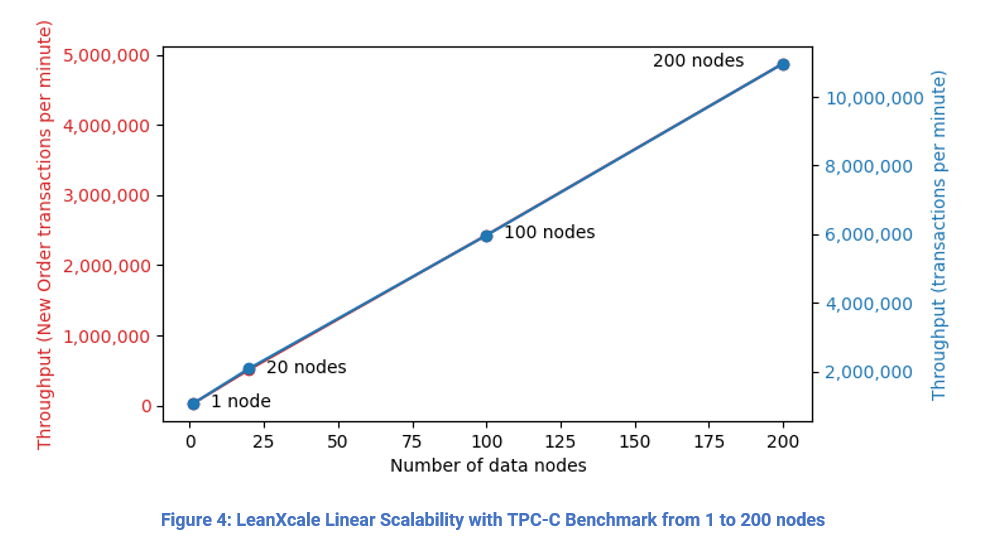
On top of KiVi and the transactional manager sits our distributed SQL query engine. The SQL query engine enables access to the data using SQL. It provides full SQL and JDBC and ODBC drivers to access the database. The horizontal scalability delivered by LeanXcale is linear, which is the optimal type of scalability. If one uses a cluster with 200 nodes, then one gets 200 times the throughput of a single node. Although it sounds natural, it is very hard to obtain and most distributed databases scale only logarithmically (centralized databases exhibit null scalability), which prevents much improvement of the throughput of a single node deployment. In Figure 2, it can be seen the linear scalability achieved by LeanXcale with the industrial benchmark for operations databases, TPC-C.
Use Case Example: Scaling IT Infrastructure Monitoring (ITIM)
A monitoring tool is a system that retrieves information from different devices, agents or probes. It identifies the topology and creates a set of metrics and KPIs. These metrics/KPIs allow us to forecast the behavior of the system, spot problems and identify their root cause. They persist in a database. When the volume of metrics grows, several strategies need to be used. The most common are sharding and the usage of complex architectures.
Let’s describe a fictional story in ITIM, featuring a new on-line monitoring company LxCMon, to characterize the limitations of these patterns and later highlight the benefits of linear scalability in this context. In this story, LxCMon has developed a multitenant SaaS platform to monitor VMs’ behavior. After some time, the SaaS platform starts to have remarkable traction in SME and corporate markets. At this point, the DevOps team realizes that their database’s capacity is about to be overwhelmed. The engineering team decides to use explicit sharding of the database to address the scalability issue, so the customer base is split across several isolated database instances.
However, the metrics from corporate customers become massive, LxCMon needs to persist with them in several independent database instances. Since some global metrics require the information stored in these independent database instances to be aggregated, LxCMon cannot provide their corporate customers with their computation in real-time. This lack of real-time information negatively impacts their forecasting ability and their MTTR (Mean Time-To Repair).
On the other hand, some SME companies are disruptive startups and others ultimately disappeared. Balancing the data across the different shards is an impossible task, resulting in some of them being overloaded while other ones are underloaded with the consequent waste of capacity. Deciding how to split the metrics from customer-base across the independent database instances to reduce the HW footprint becomes a very challenging moving target.
To solve all these issues, the LxCMon engineering team implements a complex architecture with several types of databases. This complexity increases the total cost of ownership because of more licenses, higher footprint, multiple copies of the data resulting in higher storage costs and more required experts on different database engines. Furthermore, as the different database engines evolve, troubleshooting becomes more difficult because it can be a problem in one engine or another, or in the integration. This yields a price increase with longer outages, as the more complex the solution, the longer the process to find the issue and solve it becomes. This makes the platform less appealing for users that have to pay more for the same monitoring tool with a quality of service that keeps degrading over time. On the other hand, the time to develop new functionalities gets longer due to platform complexity. Due to the longer time to market (TTM), the product becomes less competitive and the level of disruption decreases. Ultimately, LxCMon traction declines.
A database that scales linearly would have been the optimal solution for a monitoring platform such as LxCMon. A monitoring solution based on a linearly scalable database can:
- Maintain the same total cost of ownership (TCO) per collected metrics independently of the parallel amount of collected metrics.
- Have a simple inventory process where every metric is in the single database.
- Reduce the TTM since the architecture is just as simple as the one needed for a small monitored system, thus overcoming the scalability limitations without increasing software complexity.
- Since there is a unique global database that is fed in real-time, the MTTR is reduced due to the forecast accuracy being increased. That enables the general adoption of machine learning techniques, resulting in a boost of AIOps.
Scalability Issues with SQL Databases
SQL databases mostly resort to cluster replication (see our blog post on Cluster Replication). Cluster replication lies in using full replication at all nodes to be able to scale out the read workload. However, the write workload has to be processed at every node, which yields logarithmic scalability (see Figure 2). This means that, at most, the throughput of a single node can be multiplied by 2 or 3 using a cluster of 5 to 10 nodes, which is highly inefficient.
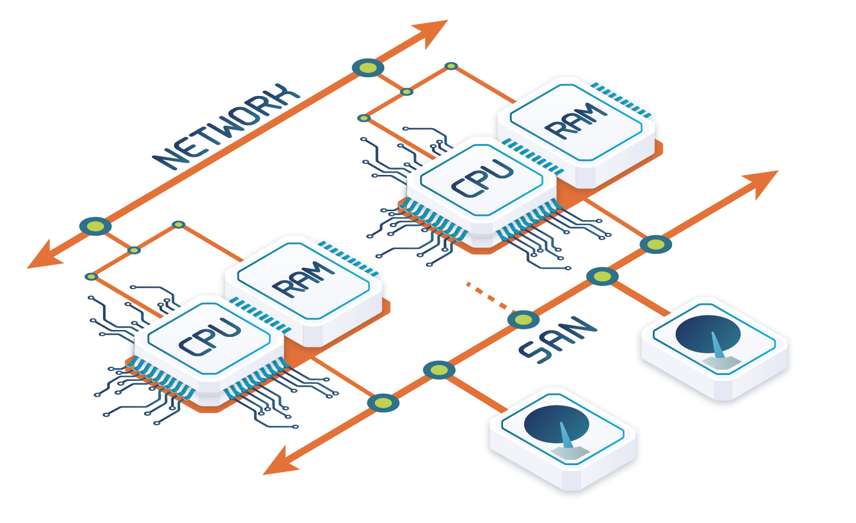
Some other databases rely on a shared disk architecture (see our blog post on Shared Nothing for an overview of this architecture and comparison with other database architectures). Shared disk architecture needs to perform distributed locking across the different nodes to avoid the two nodes updating the same disk block simultaneously. This distributed locking means broadcasting the lock request to all the nodes over each data block that is being modified, and to broadcast the changes in the block to all the nodes with a copy of the block, before releasing the lock. This severely limits the scalability of the approach and yields logarithmic scalability, also resulting in logarithmic scalability as with cluster replication.
Query Issues with NoSQL Data Stores
Some NoSQL data stores, in particular, some distributed key-value data stores are able to scale out linearly. However, they do so at the cost of losing ACID transaction properties, which results in issues with data consistency in the advent of failures and highly complex recovery. Furthermore, NoSQL data stores cannot join data across tables and their query capabilities are quite limited.
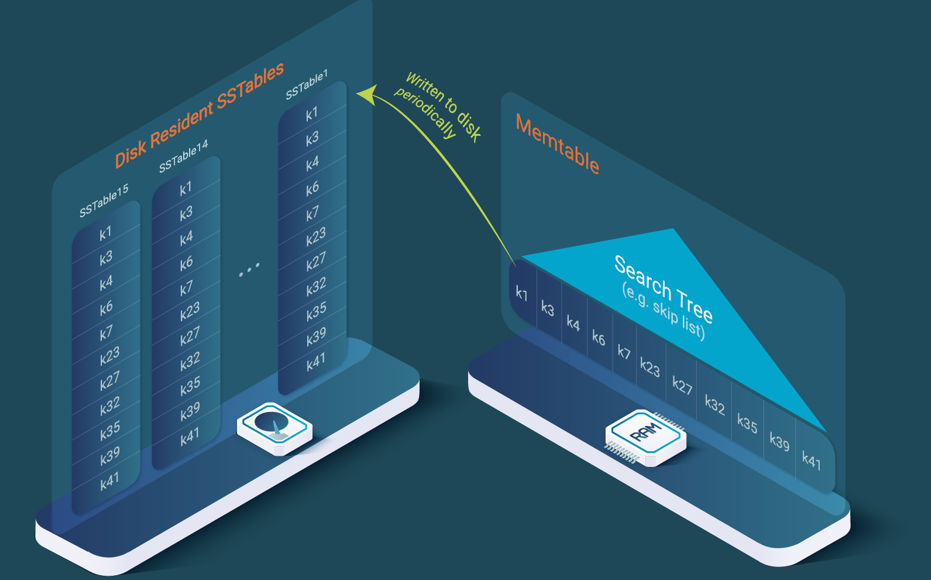
But the most important issue is that NoSQL data stores are especially inefficient at processing queries (see our blog post on B+ trees, LSM trees and SSTables). The reason is that they use SSTables to store data, which results in an order of magnitude more disk reads for any range query than an SQL database based on B+ trees. Additionally, NoSQL data stores have a flexible schema, which is an advantage for many applications, but is several times less efficient than accessing data on a fixed schema as with an SQL database.
LeanXcale Linearly Scalable Transactional Management
Traditional and modern transactional databases do not scale or, at best, scale in a very limited way. This is because at some point of the transactional processing, they perform some actions in a sequential manner. This means that either a single node bottleneck is created, or they have a centralized component that performs the transactional processing. LeanXcale is able to scale-out to 100s of nodes thanks to its radical patented technology to transactional processing called Iguazu. With this patented method, transactions are processed and committed fully, in parallel, without coordination across them. Consistency is achieved by making concurrent snapshots of committed data visible as soon as they become consistent, instead of delaying the execution or forcing sequential processing. In other words, instead of executing transactions sequentially or centrally to enforce consistency, transactions are allowed to be executed fully in parallel and in a distributed way. Whenever a new consistent snapshot of the data is available, it is then made visible to applications.
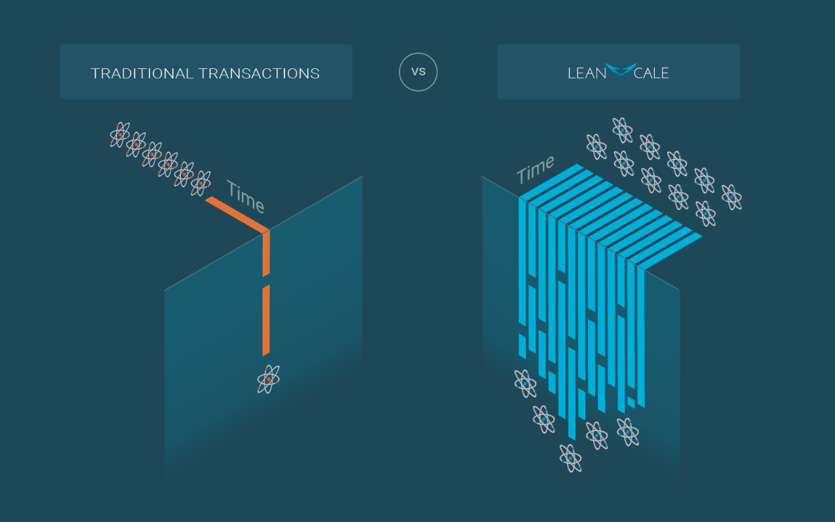
In order to scale, LeanXcale avoids a centralized transactional manager that would become a single-node bottleneck and decomposes the ACID properties into its basic components, scaling out each of them.
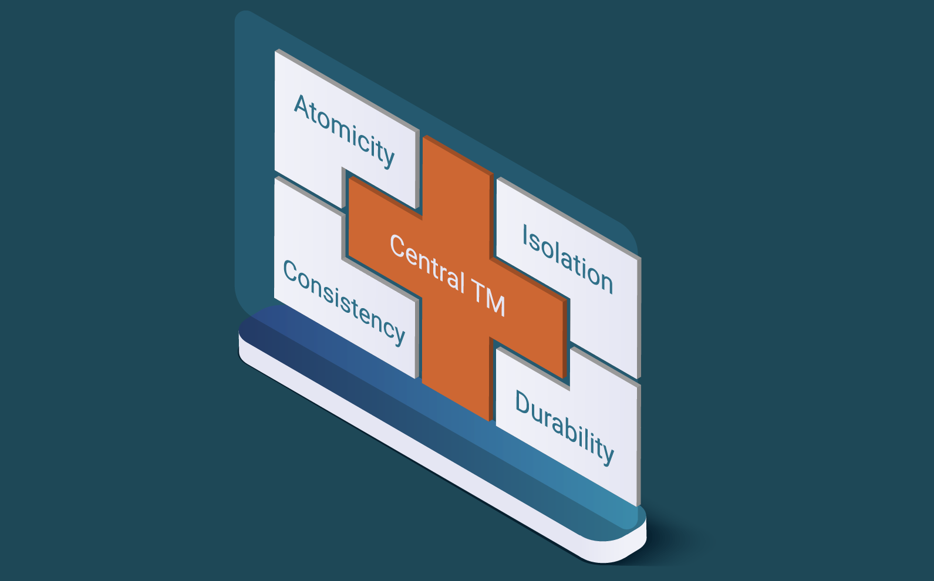
A transactional database has to care about Atomicity, Isolation, and Durability. Consistency, in the context of the ACID properties, is the responsibility of the application to transform a consistent state of the database into another consistent state. That is to say that the application should be correct and not introduce inconsistencies into a consistent database. The database can only help by providing mechanisms to check for integrity constraints to detect errors on the application transactions. What is typically understood as consistency is the combination of the other three properties. LeanXcale further decomposes isolation into the isolation of reads and isolation of writes, since they require different mechanisms. It scales out each of the properties individually in such a way that the combination provides ultra-scalable, full ACID transactions.

LeanXcale uses the components depicted in Figure 8 for delivering each of the ACID properties in a scalable manner.
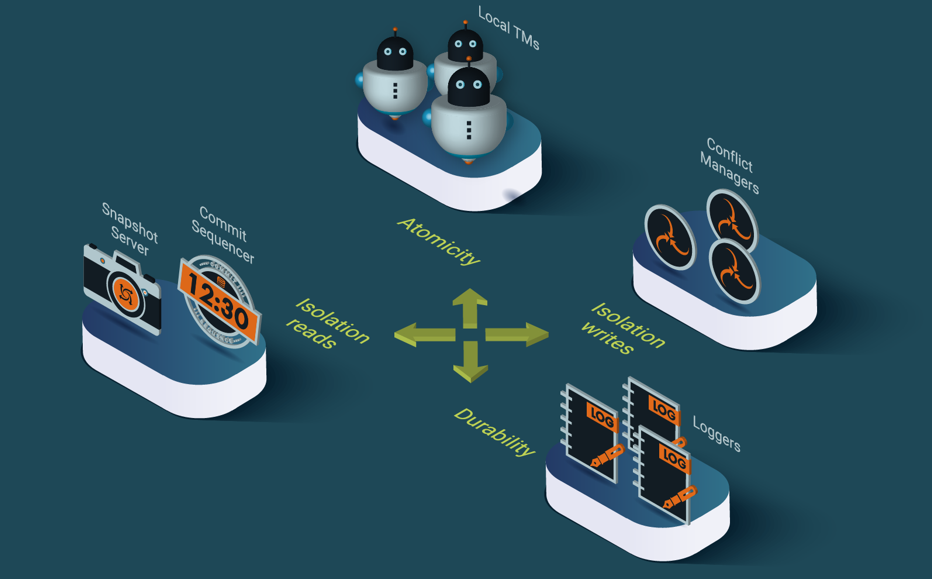
LeanXcale Scalable Distributed Storage and Query Processing
LeanXcale scales out all the layers of the database linearly. The hard one is transactional management, which we introduced in the previous section. Furthermore, the distributed storage that runs on KiVi and the distributed query processing engine are both linearly scalable. KiVi uses horizontal partitioning of tables to distribute the load over a table across multiple KiVi nodes. KiVi implements intra-query parallelism and intra-operator parallelism for all the algebraic operators it provides (scan, filtering, aggregation, grouping and sorting). This provides the basis for fast query processing (see Figure 9). The SQL query engine actually pushes down all algebraic operators to KiVi, below a join in a query plan.
The query engine itself is distributed and each query engine instance runs a subset of queries. Intra-query and intra-operator parallelism are currently provided for all algebraic operators below a join, and we are currently implementing intra-query intra-operator parallelism for joins, yielding a full OLAP query engine.
Main Takeaways
A critical requirement of monitoring systems is providing a 360º view of all monitored systems and, since customers will have different, changing sizes, this needs to be achieved at any scale. This requirement is typically not addressed by SQL databases that do not scale out linearly. This becomes a limiting factor when dealing with multi-tenant monitoring platforms as well as large customers that require infrastructure monitoring of large-scale data centers.
Some NoSQL databases (key-value data stores) can scale linearly. However, they miss SQL query capabilities, ACID properties, and require learning a proprietary API. The lack of ACID properties results in data inconsistencies in the advent of failures, thus requiring very complex recovery processes or simply living with inconsistent data and the consequent low quality of service to the customers. NoSQL APIs are very limited compared to SQL and do not support joins and other algebraic operators. If they do, it is only in very limited versions. Furthermore, query processing in NoSQL data stores is highly inefficient because they rely on SSTables as a storage approach, which is an order of magnitude worse than using B+ trees as in SQL databases. LeanXcale provides seamless linear scalability and combines the efficiency of NoSQL to ingest data with the ease and efficiency of querying the data with SQL. This combination of features allows it to provide a 360º view of monitored systems at any scale, resulting in a high reduction of TCO, the TTM and the MTTR. This provides a better user experience to customers and higher benefit margins to the company selling the monitoring services.
References

[Özsu & Valduriez 2020] Tamer Özsu, Patrick Valduriez. Principles of Distributed Database Systems, 4th Edition, Springer, 2020.
Related Blog Posts






About this blog series
This blog series aims at educating database practitioners on the differential features of LeanXcale taking a deep dive on the technical and scientific underpinnings. The blog provides the foundations on which the new features are based and provides the reader with facts that allow them to compare LeanXcale to existing technologies and to learn its real capabilities.
About the authors
- Dr. Ricardo Jimenez-Peris is the CEO and founder of LeanXcale. Before founding LeanXcale, for over 25 years he was a researcher in distributed database systems, director of the Distributed Systems Lab and a university professor teaching distributed systems.
- Dr. Patrick Valduriez is a researcher at Inria, co-author of the book “Principles of Distributed Database Systems” that has educated legions of students and engineers in this field and, more recently, Scientific Advisor of LeanXcale.
- Mr. Juan Mahillo is the CRO of LeanXcale and a former serial Entrepreneur. After selling and integrating several monitoring tools for the biggest Spanish banks and telco with HP and CA, he co-founded two APM companies: Lucierna and Vikinguard. The former was acquired by SmartBear in 2013 and named by Gartner as Cool Vendor.
About LeanXcale
LeanXcale is a startup making an ultra-scalable NewSQL database that is able to ingest data at the speed and efficiency of NoSQL and query data with the ease and efficiency of SQL. Readers interested in LeanXcale can visit the LeanXcale website.