

KEY CONCEPTS
A database is essentially “an organized collection of data.” Of course, this idea of being “organized” holds an entire world within, which is a primary reason why databases have become one of the most complex systems in computer science.
Even more, the topology of the data stored and how they are used define their management strategy. A common use case when generating and using data is the time-series, where the time when data was recorded is stored sequentially. Here, the data begins at a point in time and continues to be generated forever.
As a database receiving data with times, the following three features are required to be performed: storing the data, querying the data, and archiving old data. For this post, we focus on this first requirement. First, we will review several important concepts related to this use case to help us understand the challenges that can arise when storing this type of data.
- Data distribution is a crucial feature in database performance that allows multiple strategies related to parallel processing as well as distributing loads between various machines. The data distribution concept is directly related to partitioning and is part of the idea of how databases are “organized.”
- Working set is also important in database performance that represents the amount of data that a process requires during a time interval. For the use case we cover here, the working set tends toward infinity.
- Low latency memory is important as reading or writing data varies in performance if it performed from RAM, the hard disk, or the network.
- Primary Key is the minimal set of columns that uniquely specify a database record tuple so you can know where the data is located, enabling reading or writing with precision. In relational databases when you are inserting in an order way, by following a primary key, you need to know where to put the new key as it arrives.
- Cache is the component that temporarily stores data so that future requests for the data can be served faster.
- Hit ratio is the percentage of accesses that result in the cache.
USE CASE AND CHALLENGE
A database’s goal for partitioning is to split information for easy management. So, a table may be partitioned based on a column that has a meaning for a business application using the data. For example, let’s consider data containing phone number ranges, worker identifiers, or IPs. The type of data will guide you into an appropriate system distribution based on the data. However, for our use case, the data volume will continue to grow based on this partitioning that uses a timestamp with increasing value.
When storing continuous data, an implicit requirement is not to lose performance over time, which is difficult to achieve because the working set never stops growing while resources may be limited.
Next, we’ll consider what happens over time, and when the trouble can begin. Remember, your database is still only a computational process that runs on a machine and, just as with any other process, will have limited memory resources.
First, data insertion begins when the database typically inserts the data and uses RAM to manage the information. The database will relay the data in a background process to write the information to the disk to make it durable.
Because the process of writing to disk is much slower compared to inserting data into RAM, the RAM is leveraged as a buffer. The amount of RAM available for the process should be limited (either by software configuration or a hardware limit). Otherwise, if the load continues, then the amount of free space of RAM will decrease over time, and the write-to-disk process will not be able to free up enough RAM because the insertion process is faster.
So, as the load continues, the amount of available RAM is exhausted, and the database process slows the insertion performance down to the base level of the I/O disk bandwidth.
Finally, you will still need to write the data to the disk, but you can select the order in which specific data is written. For this process, the cache and hit ratio can enhance the performance.
Typically, the data includes an unknown dispersion related to the initial partitioning of the business application. In other words, when the working set has grown large enough to no longer fit into the available memory, a key that is not usually in the cache must be found to know where to put the new incoming key. This procedure requires an extra disk I/O to identify where to write the key, which is the source of trouble.
SOLUTION
Considering this use case, the LeanXcale database has implemented a mechanism to keep the insertion performance consistently high over time. Data storage servers are available to manage one or more partitions, where each server maintains separate memory resources. This feature enables the servers to independently manage the resources dedicated to each partition.
The key solution is to implement a second dimension partitioning that splits the working set based on the values of the column that continues to grow. In this use case (and in many cases), this additional column is the timestamp.
With this approach, the cache holds the rows with the most recent timestamp. So, when writing these to the disk, the cache can also store the directions of where on the disk to write. This allows the cache not to be waisted with older data no longer needed because the new keys arrive with recent timestamps and they will keep growing.
This process reduces the impact of the data dispersion because a map exists in memory with the range of the business application’s partitioning that only for the recent timestamps.
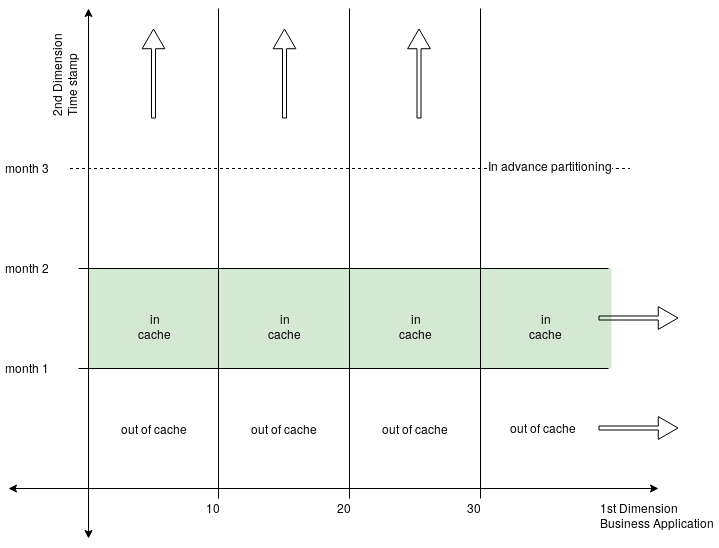
Moreover, if this bi-dimensional partitioning is combined with monitoring the partition size, then the partitions can be auto split in advance to avoid data movements, which is the current implementation in the LeanXcale DB.
ADDITIONAL THOUGHTS
With the mechanism described above, consistent performance is maintained over the entire time the continuously growing data is inserted. With LeanXcale, this process can be performed not only with a timestamp column but with any column type. Also, the process can be split into more than one dimension, as much as is needed by the use case.
WRITTEN BY

José María Zaragoza Noguera
Software Engineer at LeanXcale