

Motivation: Reduce the intake time in financial/insurance data pipelines
The ability to make informed decisions has become a differential asset for the organizations’ success. Companies must collect high volumes of data from several sources and process it to extract information. This fact is most important for some departments, such as the actuaries, risk control or debt recovery, and others who need this information to perform normal activities. Thus, data-driven organizations require data stacks that provide the results from heavy data processing within a limited time window.
However, this creates extra pressure on databases that must reconcile two opposing features: Fast data ingestion and efficient querying. The current dichotomy splits the database spectrum into two different categories: NoSQL and SQL:
- One advantage of NoSQL technology, and more particularly, key-value data stores, is that it is incredibly efficient at ingesting data. However, queries are high inefficient.
- SQL databases are the opposite: They are very efficient at querying data, but ingest data very inefficiently, and thus slowly.
In a normal financial company, most of these processes use SQL databases, mainly for historical reasons. The relational database’s inefficiency at intaking data highly increases the processing time. Other organization departments require the result of this process within a fixed time window. If the processing time is too long, any unexpected problem results in not completing the process within the time window and creates an organizational risk of preventing the other organization departments from performing their regular tasks properly.
How and why can technical architects accelerate data ingestion with LeanXcale? Let’s examine it in detail.
Why SQL databases cannot perform quick data intake
Regular SQL databases use as data structure a B+ tree. This underlying data structure allows SQL databases to query efficiently. However, it is more inefficient in data intake. Why? Consider that a common financial data process handles datasets that cannot be maintained in memory, for instance, a 1TB table. The B+ tree would grow to six levels to store all the data. If the database runs on a node with 128 GB of memory, it will hold less than 25% of the data in the cache, typically those nodes from the root and levels close to the root (see Figure 1).
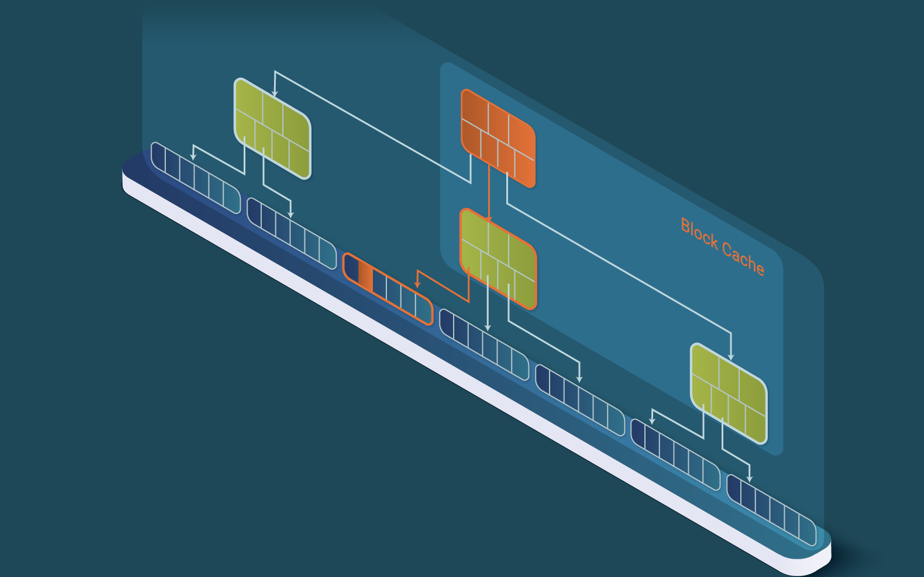
In this example, for every insertion it must read an average of three data blocks from persistent storage to reach the target leaf node, in our example, this means reading an average of three blocks from persistent storage. These read blocks will all cause the same number of blocks to be evicted from the cache, causing an average of 3 blocks to be written to persistent storage. This means that a single data row is causing 6 I/Os. This is why SQL databases ingest data very slowly.
Why not use only a NoSQL datastore?
If we only use a NoSQL data store to perform this type of process, we will get an efficient intake, but poor overall performance. Let’s see why.
Regular key-value data stores rely on SSTables that cache updates and write them to disk periodically on a different file, thus optimizing I/Os by writing many rows in one operation. However, queries become very slow. Let’s jump into the details.
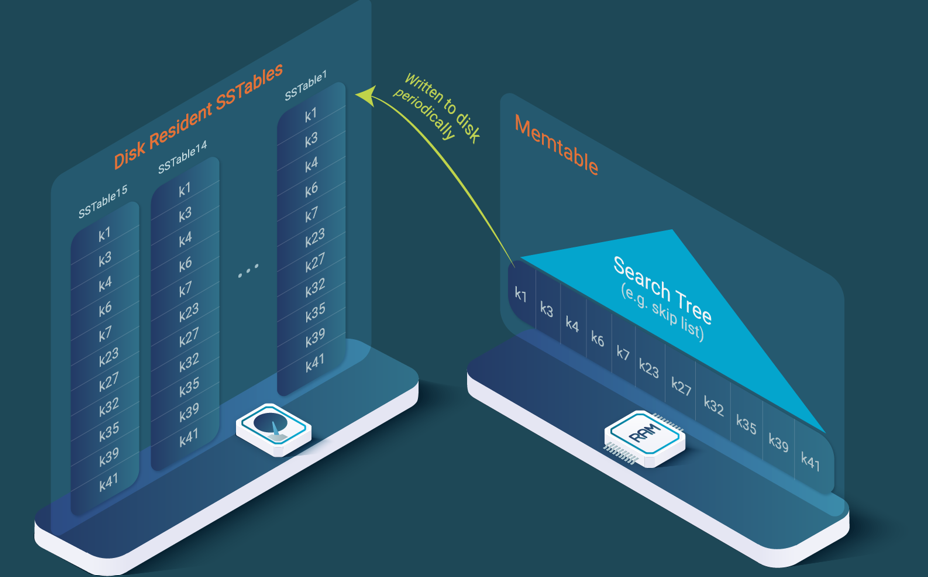
In the case of an SStable, a specific horizontal data fragment will be spread across many files, and the data store has to access all of them to execute the range query. This spread causes great inefficiency when reading.
SSTables improve when data is stored as B+ trees in each SSTable, so the search must be performed across several B+ trees.
Let’s assume there are 16 SSFiles, each with a B+ tree, so we need to perform the search of the first key of the range in 16 B+ trees that will be 16 times smaller than a single B+ tree with all the data. Let’s assume each B+ tree has 1024 blocks. So, each search will need to access log (1024) blocks = 10 blocks. Since there are 16 searches, 160 blocks must be read. For a single B+ tree, we would have searched 16384 blocks and read log(16384) = 14 blocks. The NoSQL solution reads 160 blocks, while SQL reads 14 blocks, more than an order of magnitude more blocks.
How to ingest and process quickly? The LeanXcale Solution
How does LeanXcale solve the problem? There are several aspects of the answer, but we want to highlight that LeanXcale’s relational key-value datastore is built using a hybrid data structure. This versatile structure is efficient at both ingesting and querying data.
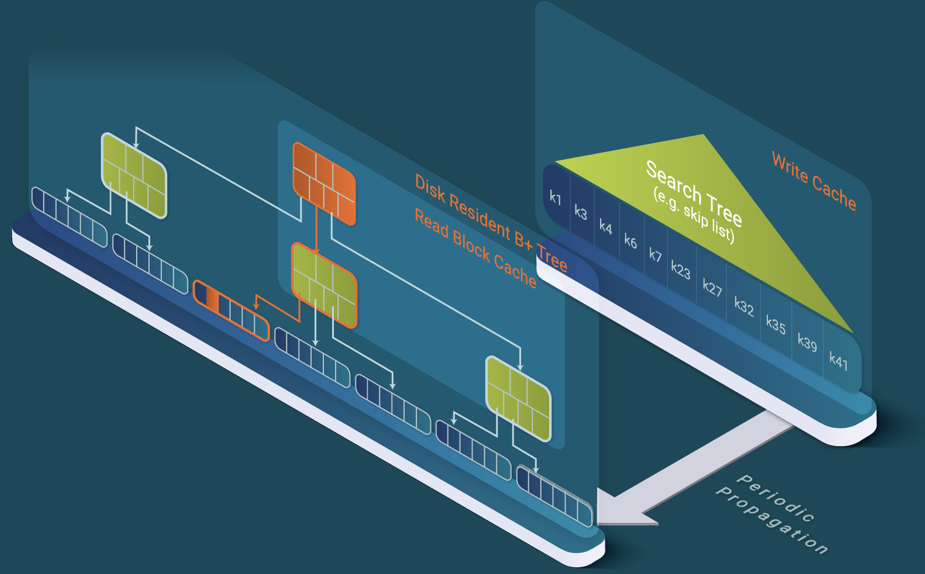
Let’s look at it in detail: This novel data structure is the B+ tree plus the two caches, specialized in reading and writing respectively. The write cache stores all insertions, updates, and deletions of rows, while the read cache is an LRU block cache that stores the most recently read blocks.
Additionally, LeanXcale stores, as in the regular SQL database, the persistent data in B+ trees (see Figure 3). A B+ tree is a search n-ary tree. Data are only stored on the leaves.
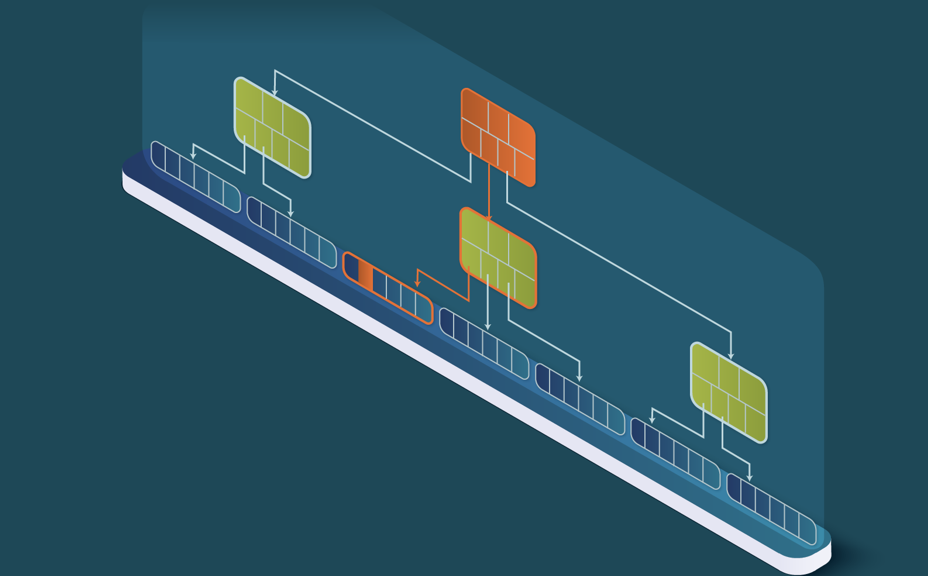
The goal of the intermediate nodes is to enable the logarithmic search.
As shown in Figure 4, the stored keys are the split points of the data on the different child subtrees. With the search for a particular key, sk, one subtree can be chosen at each node of the tree, since it is known that the other subtrees will not contain that key. When sk is higher than k1 but lower than k2, we know the data can only be in the middle subtree. This iteration continues until the leaf node containing the searched row is reached (see Figure 3).
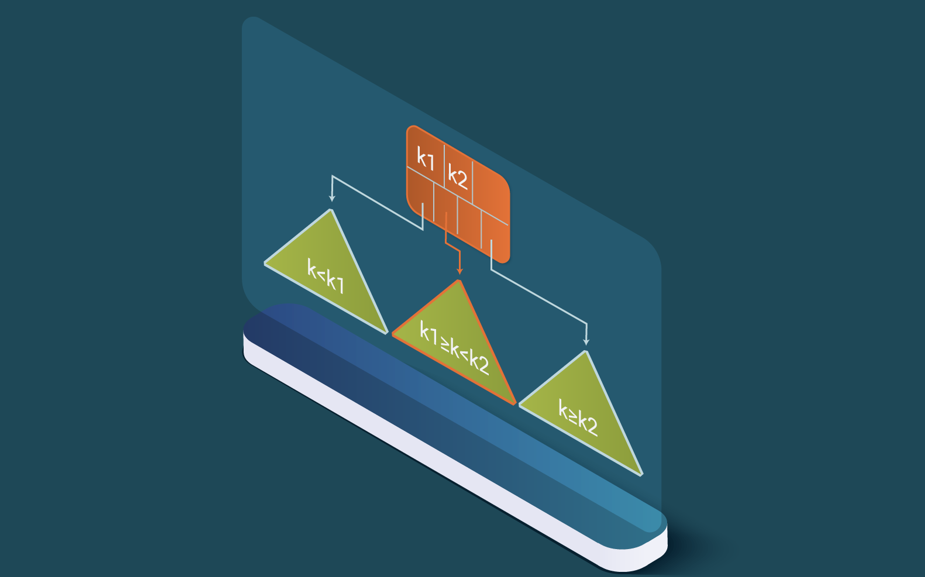
The reason why LeanXcale is efficient is that the nature of the B+ search tree guarantees that the leaf node(s) containing the targeted rows can be reached only reading a logarithmic number of blocks.
LeanXcale uses a write cache to overcome the inefficiency of SQL databases that require multiple IOs to insert a single row (see Figure 5).
What are the other characteristics that speed-up LeanXcale data intaking?
In addition to this versatile hybrid data structure, LeanXcale intaking velocity is accelerated by other features:
- LeanXcale’s architecture is designed for NUMA architectures, which also contributes to its efficiency. KiVi servers, the LeanXcale data stores, are single-threaded per core and allocated memory of the NUMA unit of the core, so it accesses only local memory of the NUMA unit, preventing the expensive NUMA remote access that has a much more limited bandwidth than the local NUMA accesses.
- Ingestion of data is enhanced due to Bidimensional partitioning. It minimizes the number of read blocks from persistent storage by using a B+ tree and caching blocks (see our blog on Bidimensional Partitioning).
- The third factor providing better efficiency is LeanXcale’s native NoSQL interface, which can perform the insertions/updates without the extra SQL overhead. LeanXcale provides both SQL and NoSQL interfaces. LeanXcale is a relational database consisting of the three traditional subsystems: 1) a data store, 2) a transactional management system, and 3) a SQL query engine. In the case of LeanXcale, the data store uses a relational distributed key-value. This data store provides a direct key-value interface that provides very high rates.
A Real Example: Informa Dun & Bradstreet
Informa D&B are a leading business information and credit scoring company in Spain, Portugal, and Colombia, and are a part of the Dun & Bradstreet network.
Informa stores all the financial data of more than 9 million Spanish economic entities, with a depth of more than 30 years. Once a week, they copy all this information in an Oracle database to process and create partial copies for other corporations. This process is called marketing database, and it is one of the most important revenue streams for Informa D&B. They need to process more than 1.7 billion rows of this marketing database. It is a process that was run over weekends took more than 27 hours to ingest it on the leader database, and the company was very exposed to failures since there was no time to repeat the process during the weekend and customers did not have the data they bought during the following week. This meant that it was mandatory to drastically reduce the duration of this process.
After migrating to LeanXcale, the process runs 72 times faster. What needed more than 27 hours to be ingested, is now performed in 22 minutes. As a result, operational risk is reduced, because the process can be executed on a daily basis, or as many times as needed, even in real-time if necessary, and they can create new products and services that were previously impossible to provide, as for instance, real-time credit scoring.
To know more about this case you can check this webinar: Informa’s CTO, Carlos Fernández, tells us how Informa is preparing its data architecture to move from managing gigabytes to petabytes by using LeanXcale.
Main Takeaways
The financial/insurance industry’s data pipeline performance is highly impacted by the data intake time. Most of these pipelines use SQL databases. SQL is very efficient at querying data since only a logarithmic number of blocks is required to be read. However, ingesting data is very inefficient since each row must be inserted with several IO operations.
NoSQL data stores are not a solution since, although they are efficient at ingesting data, they are more than an order of magnitude less efficient when it comes to querying data.
By using its write cache and, when necessary, bidimensional partitioning, LeanXcale can query data as efficiently as SQL and ingest data as efficiently as NoSQL thanks to its hybrid design based on new inventions. LeanXcale is more efficient than existing databases in modern NUMA architectures thanks to its NUMA-awareness. Finally, LeanXcale’s dual interface allows it to write data very efficiently via the native API, and query data very easily and efficiently via SQL.
LeanXcale can make a data pipeline 72 times faster than one based on the market leader.
References

[Özsu & Valduriez 2020] Tamer Özsu, Patrick Valduriez. Principles of Distributed Database Systems, 4th Edition, Springer, 2020.
Related Blog Posts



About this blog series
The goal of this blog series is to inform database users and maintainers of the features of LeanXcale that differentiate from others, taking a deep dive into the technical and scientific underpinnings. The blog provides the foundations upon which the new features are based and provides the reader with facts, allowing a comparison of LeanXcale to existing technologies, and provides an understanding of its real capabilities.
ABOUT THE AUTHORS
- Dr. Ricardo Jimenez-Peris is the CEO and founder of LeanXcale. Before founding LeanXcale, for over 25 years he was a researcher in distributed database systems, director of the Distributed Systems Lab and a university professor teaching distributed systems.
- Dr. Patrick Valduriez is a researcher at Inria, co-author of the book “Principles of Distributed Database Systems” that has educated legions of students and engineers in this field and, more recently, Scientific Advisor of LeanXcale.
- Mr. Juan Mahillo is the CRO of LeanXcale and a former serial Entrepreneur. After selling and integrating several monitoring tools for the biggest Spanish banks and telco with HP and CA, he co-founded two APM companies: Lucierna and Vikinguard. The former was acquired by SmartBear in 2013 and named by Gartner as Cool Vendor.
ABOUT LEANXCALE
LeanXcale is a startup making an ultra-scalable NewSQL database that is able to ingest data at the speed and efficiency of NoSQL and query data with the ease and efficiency of SQL. Readers interested in LeanXcale can visit the LeanXcale website.