
As a crucial component of the toolset required to establish an effective operational or Big Data architecture with LeanXcale, we provide the Kafka sink connector that enables interconnection between LeanXcale and Kafka through a straightforward configuration file. Let’s see how to do it!
Kafka
Kafka is a messaging system based on the producer-consumer pattern that uses internal data structures, called topics, which temporarily store received data until someone subscribes (i.e., connects) to consume the stored data. Kafka is considered a persistent, scalable, replicated, and fault-tolerant system. In addition, it offers good read and write speeds, making it an excellent tool for streaming communications.
Key concepts
KAFKA SERVER
As a server that manages topics, Kafka listens via an IP and port. Therefore, we must boot it into the operating system with a process that corresponds to the server, such as Tomcat or JBoss. When we connect to the server to place records into a topic or consume topic records, we simply specify the name of the topic along with the IP and port on which Kafka’s server listens.
TOPICS, PRODUCERS, AND CONSUMERS
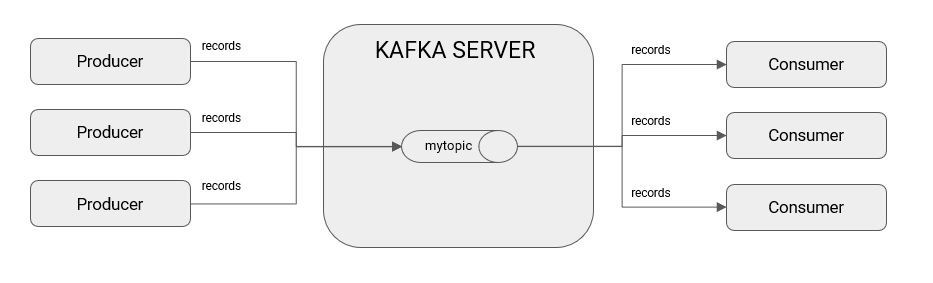
This picture illustrates the main idea of the Kafka server. A topic within Kafka acts as a FIFO tail for which one or more producers can send records (e.g., messages) to a topic, and one or more consumers can read from a topic. Consumers always read the records in the order in which they were inserted, and records remain available to all consumers, even if one has consumed it previously. This feature is achieved by keeping track of the offset per consumer, which is a sequential number that locates the last record read from a topic and is unique per consumer. With this approach, a record is ensured that if one consumer has already read it, then it remains available to all other consumers who need it because they will have a different offset from the one that previously consumed it.
If we send a record into Kafka as a producer, then libraries exist for nearly all programming languages. In Java, the following is a basic, partial example to illustrate the idea:
import org.apache.avro.generic.GenericRecord;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
Properties props = new Properties(); // Create properties configuration file
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); // Add
// Kafka server ip and port to configuration
KafkaProducer producer = new KafkaProducer(props); // Create producer
// Create record
GenericRecord recordKey = new GenericRecord(); // Create record key
// Here would be the rest of the operations to fill in the key
GenericRecord recordvalue = new GenericRecord(); // Create record value
// … Rest of statements to fill the record value
ProducerRecord<Object, Object> record = new ProducerRecord<>("mytopic", recordKey, recordValue);
// Create record producer for topic
// Send record
RecordMetadata res = producer.send(record)
On the other hand, if we want to read from Kafka as a consumer, then a basic example is:
import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecords; Properties props = new Properties(); // Create properties configuration file props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); // Add // Kafka server ip and port to configuration KafkaConsumer consumer = new KafkaConsumer(props); // Create consumer consumer.subscribe(Collections.singletonList(“mytopic”)); //Subscribe consumer // to topic named “mytopic” ConsumerRecords<Long, String> consumerRecords = consumer.poll(1000); // Get 1000 // records from the topic
CONNECTORS
The above example demonstrates how to connect to the Kafka server to produce and consume records. However, these approaches can only be accomplished if we have control over the code of the applications inserting or reading records from Kafka’s topics. If the source of our data is a database, then we will not have control over the code of that database because it is a proprietary product with a proprietary life cycle. For this scenario, connectors are available. A Kafka connector is a separate process from the Kafka server that acts as a proxy between the data sources and the Kafka server.
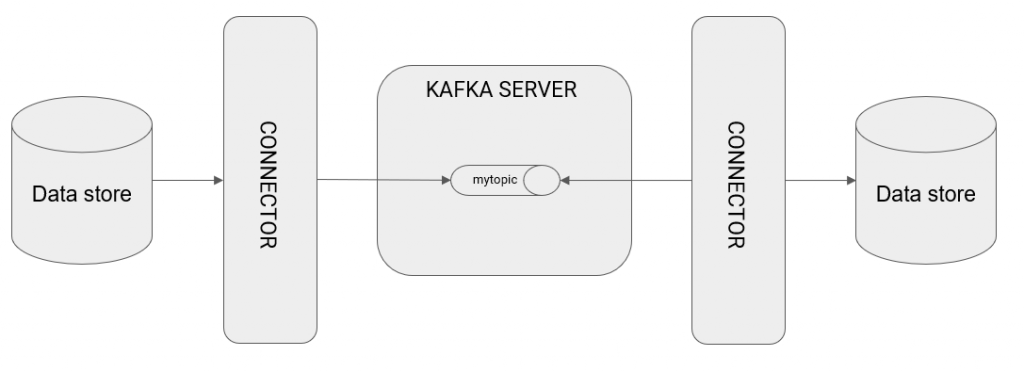
As seen in the diagram, the connectors are intermediaries between the data sources, such as a database, and the Kafka server. In this example, we have a source database from which a raised connector reads as well as inserts topics into Kafka’s server. A second raised connector reads from Kafka’s topics and inserts these into another destination database.
Predefined, open source connectors are already available to anyone to access, such as the generic JDBC connector, file connectors, Amazon S3 loop connectors, and many more for NoSQL databases, like MongoDB. LeanXcale also features a Kafka connector.
This post aims to illustrate the use of the LeanXcale connector for Kafka to read records from a Kafka topic and insert them into a target LeanXcale instance from which queries can be executed and presented in a BI viewer like Tableau or Superset. Our approach follows the architecture
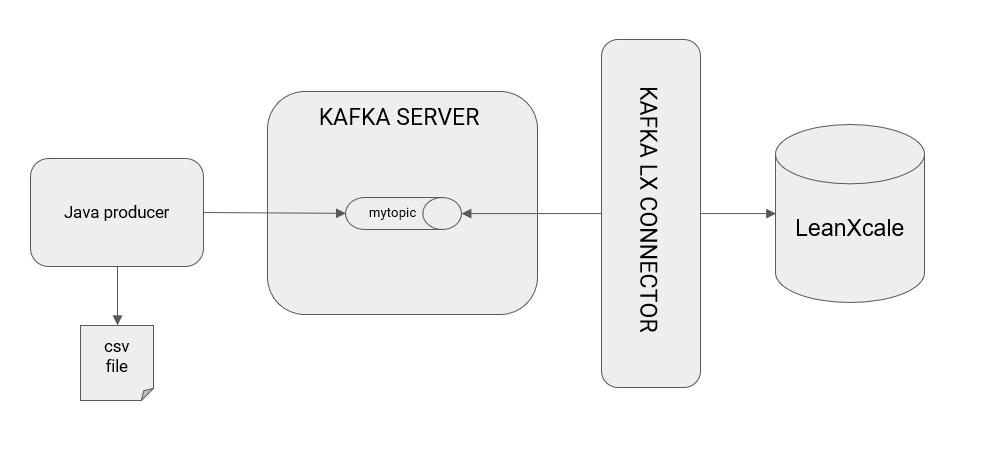
To realize this scenario, we need:
- A program (Java, in this case) to be inserted into Kafka that reads from a CSV file containing the register of public bicycle use in New York City during January 2020. The program is distributed as an executable JAR file downloadable from here, and can also be built with maven from the code, downloadable here.
- A LeanXcale instance deployed in the cloud and accessible from a local machine, which can be ordered here.
- The Kafka Connector for LeanXcale, which can be downloaded here.
The Kafka connector for LeanXcale uses the Java KiVi Direct API to insert data. This direct API provides a NoSQL interface to the database. This approach is much faster than using SQL and is tremendously powerful for inserting large amounts of data into LeanXcale.
Additional concepts required
A few additional concepts must be considered to understand the overall functioning of our proposed architecture.
DATA SERIALIZATION
The data contained in Kafka’s topics are neither text nor readable objects or entities. Instead, they are key-value structures with byte string values. Serializers are then needed to provide the data meaning. A data serializer is an entity that collects byte strings and transforms them into a readable format for a system to use, such as a JSON string or Java object. Several types of serializers are available, for example:
- StringSerializer: transforms data bytes into simple strings, or strings into data bytes.
- IntegerSerializer: transforms data bytes into whole numbers or whole numbers into data bytes. In the same way, the types Long, Integer, and Double each have serializers.
- JSONSerializer: transforms data bytes into JSON strings or JSON strings into data bytes. JSON is a framework for serializing logical objects into strings with a predefined format.
- AvroSerializer: transforms data bytes into logical objects with the special feature that it can determine the format of the data that it serializes and deserializes because of how it works with the data schemas it serializes. Because this is the serializer we use in this post, a more detailed explanation is provided below.
The implementation of the serializers is automatic from the perspective of the programmer, who only needs to leverage specially designed libraries. The Kafka connector for LeanXcale is also automatic, and the serializer is configured within a properties file. The inclusion of the serializers into our architecture diagram is illustrated as follows:
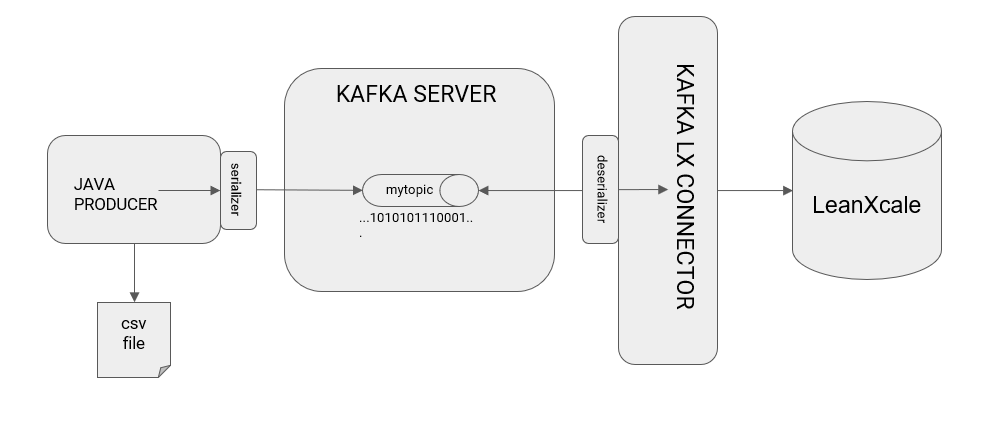
The serializer code is embedded in the producer and is executed just before sending data to the topic so that it receives the data already serialized. Similarly, the deserializer is embedded in the connector and runs just before passing the data to the connector code, so that it reads the bytes of the topic and transforms them into something understandable by the connector code.
SCHEMES
Before converted into a string of bytes, a record can obey a specified scheme. The Kafka LeanXcale connector requires that the registers it receives follow a scheme predefined by the programmer.
For example, to send records with three fields of the ID, first name, and last name of a person, an example of the defined schema is:
{
"type":"struct",
"fields":[
{
"type":"int64",
"optional":false,
"field":"id"
},
{
"type":"string",
"optional":false,
"field":"name"
},
{
"type":"string",
"optional":false,
"field":"surname"
}
],
"optional":false,
"name":"record1"
}
This schema defines the format of the records, which is represented in JSON format and contains fields for the ID, which is a long data type, the name as a string, and a surname as another string.
The Kafka connector for LeanXcale requires records to obey a schema through the use of its DDLs execution capabilities to control the structure of the target tables. In other words, if a record is received that obeys the previous schema and the automatic creation option is enabled, then the connector creates the target table with the columns corresponding to the fields specified in the schema.
AVRO AND SCHEMAS
As introduced above, the specific serializer and deserializer applied in this post is Avro because it always works with the schemas of the data it serializes. Because Kafka’s connector for LeanXcale requires a schema, this type of serialization is a good option for this scenario because it ensures that schemas exist and are configured as expected. When Avro reads or writes a byte string, the schema applied to serialize the data is always present.
In this case, when the Avro serializer converts the record created by the Java producer into a byte string, it automatically registers the provided schema, so that it is retrieved when the record reaches the connector. This feature allows to offload the Kafka topic of redundant information. Otherwise, if we did not follow this procedure with Avro, then sending the schema in JSON format would be required for each record sent to the topic. Instead, the schema is registered one time, and only the specified field values are sent to the topics.
The following is an example of a complete record:
{
"schema":{
"type":"struct",
"fields":[
{
"type":"int64",
"optional":false,
"field":"id"
},
{
"type":"string",
"optional":false,
"field":"name"
},
{
"type":"string",
"optional":false,
"field":"surname"
}
],
"optional":false,
"name":"record1"
},
"payload":{
"id":1,
"name":"Renata",
"surname":"Mondongo"
}
}
This record consists of the primary fields “schema” and “payload.” The schema field is of the type struct (i.e., an object) and contains the desired fields. The payload field contains the values of the defined fields from the schema.
Sending another record without Avro as the serializer requires sending all the content again, as in:
{
"schema":{
"type":"struct",
"fields":[
{
"type":"int64",
"optional":false,
"field":"id"
},
{
"type":"string",
"optional":false,
"field":"name"
},
{
"type":"string",
"optional":false,
"field":"surname"
}
],
"optional":false,
"name":"record1"
},
"payload":{
"id":2,
"name":"Renata",
"surname":"Porrongo"
}
}
However, with Avro, the schema is sent only once, and all subsequent records are also sent:
{ "id": 2,"name": "Renata","surname":"Porrongo"}
With this approach, we gain more speed on Kafka’s server with less redundant information transmitted.
SCHEMA REGISTRY
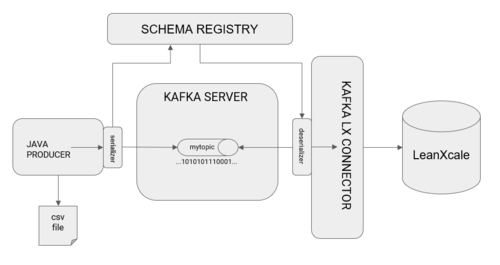
For the Avro serializer to register and retrieve the schema as described above, a new component must be introduced, called the schema registry, which is another process distinct from the Kafka server and LeanXcale connector. The final architecture for this example scenario becomes:
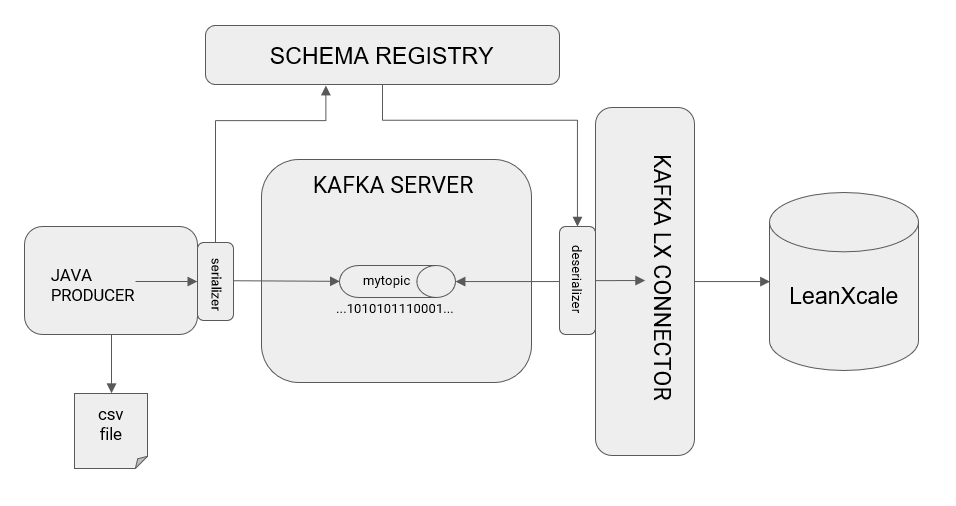
The complete flow of information is processed as the following:
- The Java producer opens a socket to the CSV file to read line-by-line.
- For each line, it creates a record for Kafka and transmits that the selected serializer is Avro.
- The producer executes a send of the log to Kafka.
- Before records arrive at Kafka, the Avro serializer stores the specified schema in the registry schema and converts it into a byte sequence.
- This byte sequence is sent to Kafka’s topic, called “mytopic.”
- Kafka’s connector queries Kafka to retrieve the stored records.
- Before the connector receives the records, the Avro deserializer connects to the registry schema and validates the records collected from Kafka against the schema, and converts the byte string representing the record into a Java object.
- The connector determines if there a table already exists in the target LeanXcale that complies with the registry schema. When one is not found, it creates the table automatically and includes the fields defined in the schema registry as columns.
- The connector stores the records collected from Kafka in the new LeanXcale table.
ZOOKEEPER
Appreciating that the execution of even this simple example, three distinct processes are required, which can also execute in parallel. So, the Kafka suite relies on a centralized process manager, such as Zookeeper, to maintain fast and efficient access to each of these processes.
Therefore, to run the Kafka server architecture, registry schema, and LeanXcale connector, a Zookeeper application must be previously initiated that is responsible for maintaining and managing the communication between the three processes involved in the distribution of records.
In practice, Zookeeper is responsible for much more. The Kafka suite also allows for defining a clusterization of its components, so, in this case, Zookeeper further manages the processes that comprise the cluster.Next week, I will show you how to execute Kafka connector for LeanXcale. Stay tuned!
WRITTEN BY

Sandra Ebro Gómez
Software Engineer at LeanXcale
10 years working as a J2EE Architect in Hewlett-Packard and nearly 2 years working in EVO Finance and The Cocktail as a Solution Architect. Now part of LeanXcale team, trying to look for and develop the best usecases for high escalable databases.