
MariaDB is one of the most popular and widely adopted relational databases in the world. LeanXcale is an ultra-scalable relational database that includes NoSQL features to provide high insertion rates. In this post, we put LeanXcale head-to-head with MariaDB to compete on data ingestion and processing against the YCSB benchmark.
WHAT IS YCSB?
The Yahoo Cloud Serving Benchmark (YCSB) is an open-source specification and program suite often used to compare the performance of NoSQL database systems. As they describe YCSB, “the goal of the project is to develop a framework and common set of workloads for evaluating the performance of different ‘key-value’ and ‘cloud’ serving stores.”
THE RULES OF COMPETITION
The following is a summary of the conditions applied to this benchmark. If you want to see more, then you can read the full benchmark.
- YCSB clients use a lot of memory, so the YCSB Client processes run on a separate machine compared to those used for the databases cluster to not interfere with the metrics.
- The YCSB Execution plan gives YCSB uses a two-stage execution plan that includes a load stage (clients only execute INSERT statements to obtain a full working set) followed by a run stage (UPDATE, GET, and SCAN).
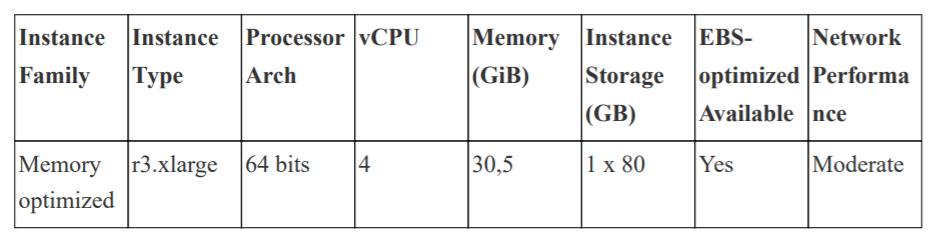
- All machines are hosted by Amazon AWS, and we requested spot instances to build the database clusters manually. These machines are “r3.xlarge,” so feature the following specs:
- LeanXcale supports the two isolation levels of Read Committed (default) and Snapshot Isolation to provide a consistent read view of the database for all transactions. For this benchmark, we use the default Read Committed isolation level. MariaDB is also set up with Read Committed that implements Repeatable Reads by default.
- The workloads in the benchmark are selected to provide a fair representation of behavior for both LeanXcale and MariaDB and are not weighted toward or against either database.
THE BENCHMARK
We use five workload scenarios in this benchmark comprised of four one-operation scenarios (read, load, update, and scan), and one mixed operation scenario (read_update).
READ throughput
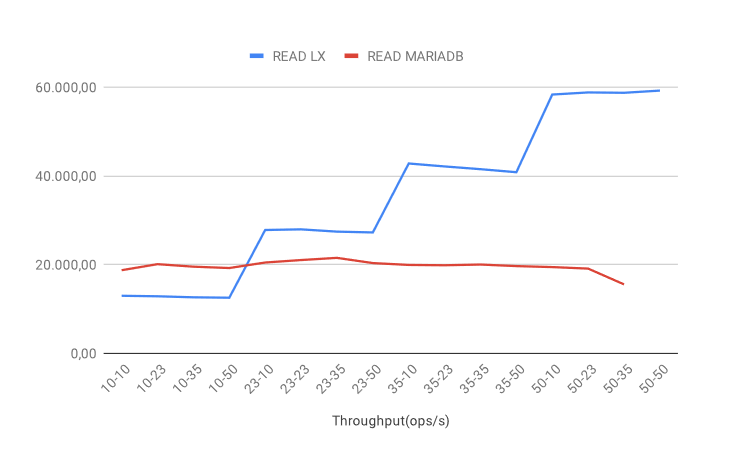
The READ operation demonstrates how the performance of MariaDB remains static with a slight drop-off as client numbers create more overhead. For LeanXcale, the scenario is clearly different as the performance increases. As soon as clients are added, the performance goes up, and we maintain stable performance by further increasing the number of threads.
UPDATE throughput
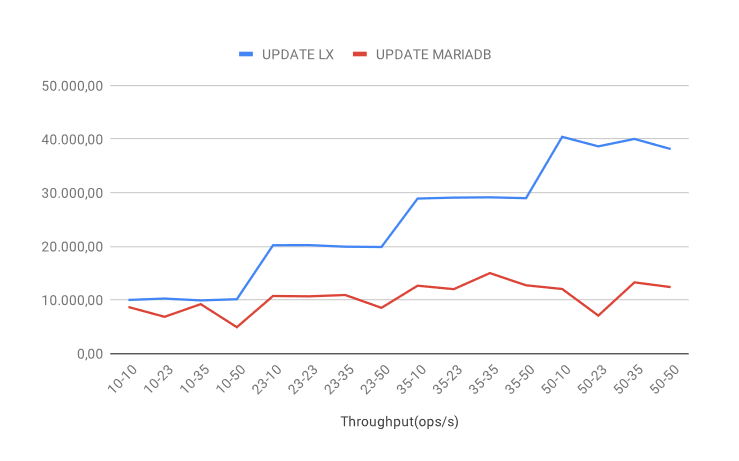
With the UPDATE operation, the results are similar to READ. MariaDB provides reasonably stable performance with a general slight increase in performance as clients and threads are added. The LeanXcale performance increases further as more clients and threads are added.
READ_UPDATE throughput
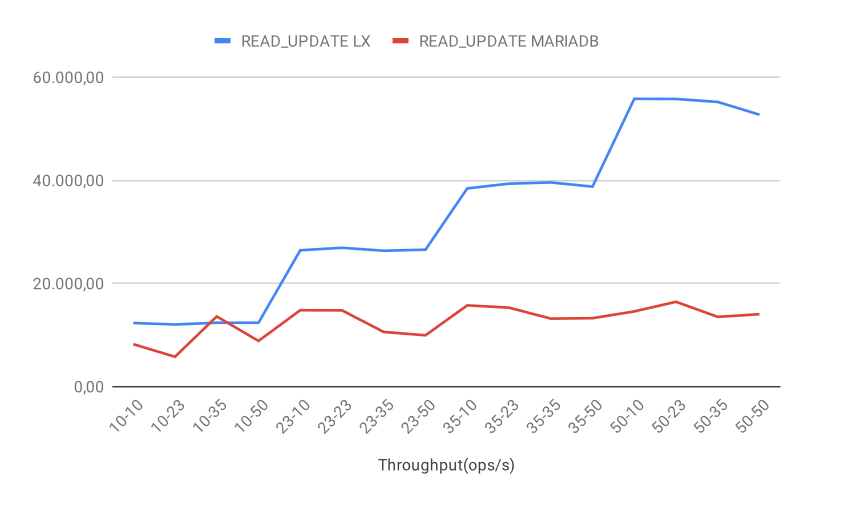
In the scenario of the READ_UPDATE mixed operation, unsurprisingly, we observe a similar outcome as READ with some aspects as with UPDATE. The MariaDB performance is reasonably stable but does not improve with increased loads. The LeanXcale performance increases as we add clients and maintains stability with more threads, and at very high loads, we experience a slight drop-off.
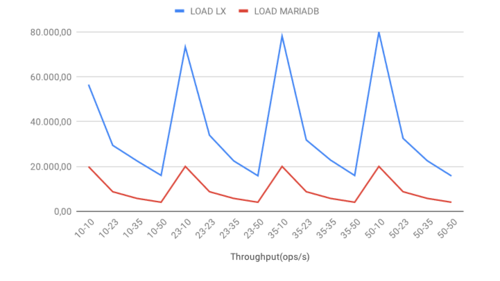
LOAD throughput
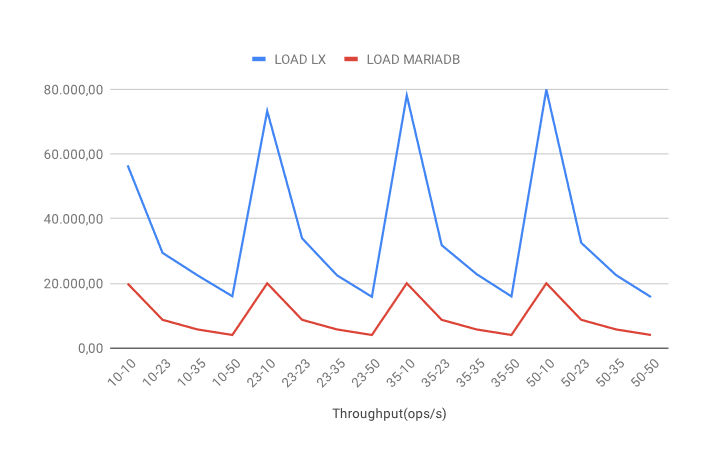
The LOAD operation workload shows a different pattern from the previous cases. For both databases, increasing the number of threads per client results in a performance decrease. There is an essential difference in this scenario. MariaDB has a performance peak at ten threads, which remains constant over an increased number of clients. LeanXcale, on the other hand, also peaks at ten threads, but this peak value increases with more clients. In practice, this result demonstrates that while the MariaDB cluster reaches a bottleneck, the LeanXcale cluster continues to accept more load.
SCAN throughput
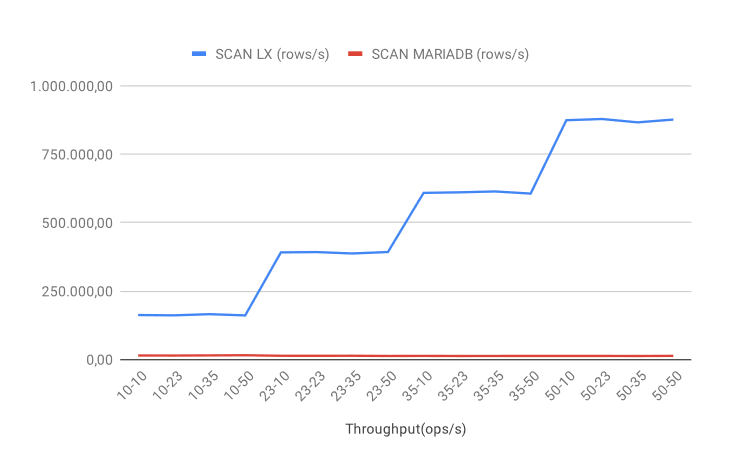
With the SCAN operation workload, the performance gap between the databases is significant that is due to an architectural problem. The MariaDB performance is not only low, but it also flat because the load is not automatically distributed over the nodes. Even though we manually distributed the nodes across the machines, we still cannot increase performance. LeanXcale, on the other hand, applies the balancing and load distribution automatically that allows enables the same performance profile: as we add clients and threads (or new nodes), the performance continually increases.
TECHNICAL ADVANTAGES
Why does LeanXcale offer such a better performance? Two features make LeanXcale so efficient for data ingestion:
- The Iguazú algorithm manages transactions efficiently distributed at any scale by allowing the linear scaling of transactions from one to hundreds of nodes while maintaining all ACID properties. In this way, 100 nodes provide 100 times the performance of one node. This patented algorithm is the culmination of more than 20 years of research in relational database scalability.
- KiVi is the LeanXcale storage engine that was developed from scratch to maximize data ingestion. As a distributed relational key-value data warehouse, KiVi provides efficiency and scalability through its key-values while maintaining the same capabilities of a standard SQL engine. The architecture avoids the cost of context changes, synchronization between threads, and avoids access to remote memory in NUMA architectures, which makes it extremely efficient.
COST STRUCTURE COMPARISON
LeanXcale offers a lower Total Cost of Ownership and a faster Time to Market compared to MariaDB. The infrastructure costs for both databases at maximum capacity used during this benchmark include:
| LeanXcale | MariaDB | |
| WRITES | 2.021 USD per billion operation month | 8.086 USD per billion operation month |
| READS | 0.183 USD per billion operation month | 10.78 USD per billion operation month |
LeanXcale costs 4 times less in writes and 58.9 times less in reads. Additionally, the LeanXcale characteristics also offer an engineering cost reduction due to its versatile database engine and data architecture simplifications as well as operational cost reduction because of the elastic management and lower cloud resources required for any workload.
WRITTEN BY LEANXCALE TEAM
