

Until several years ago, the database world was simple and all SQL. Nowadays, we also have NoSQL and NewSQL. Now the question is which one is better and for what? Let us guide you in a quick tour in this jungle of data management. In other posts, we address NoSQL (see blog post on NoSQL) and NewSQL (see blog post on NewSQL) in more detail.
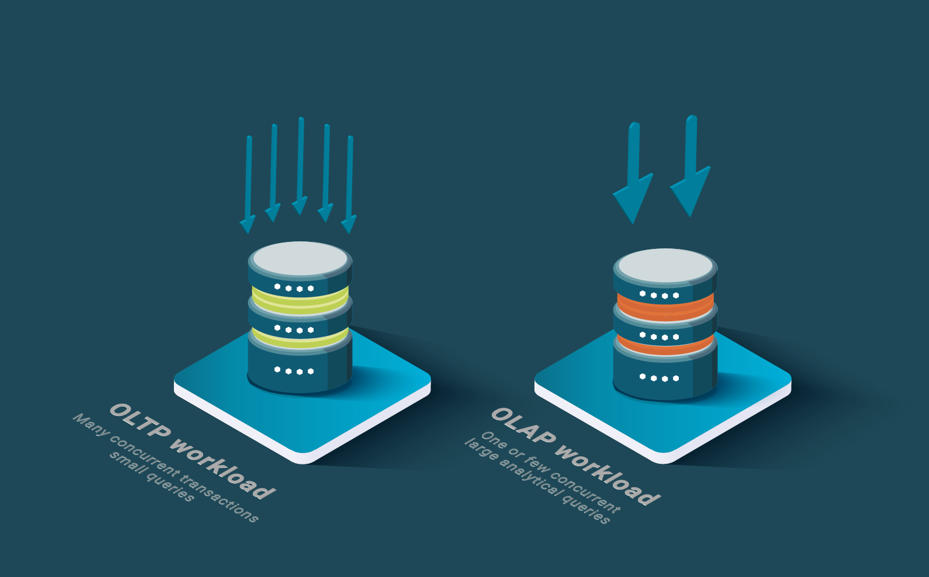
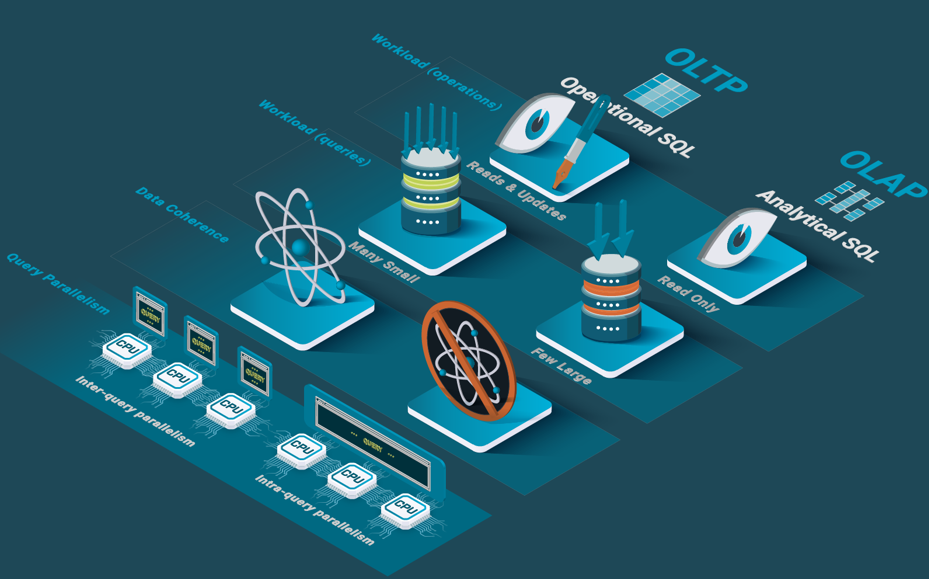
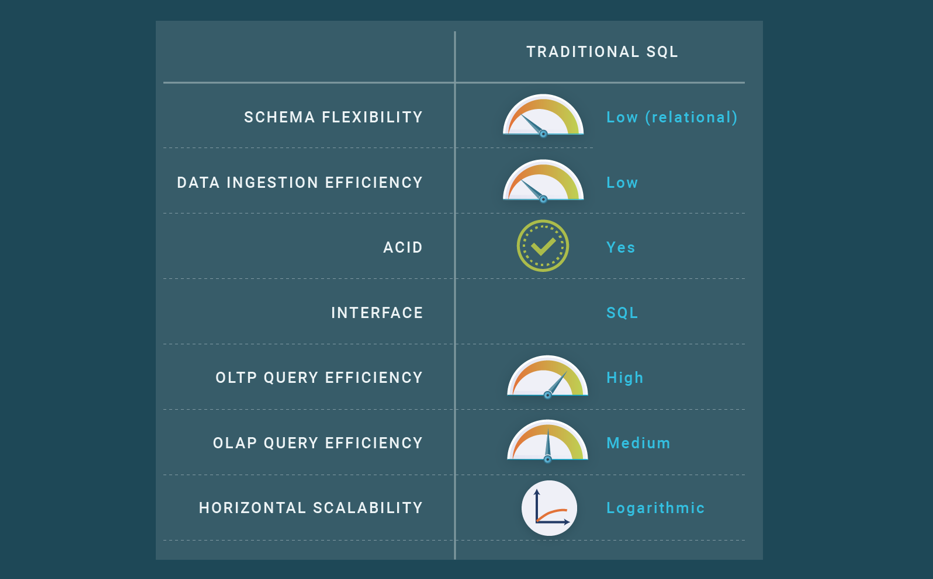
SQL databases come in two main variants, operational and analytical, which have been around for more than three decades. Operational databases have been designed for OLTP (On Line Transactional Processing) workloads. Conversely, analytical databases have been designed for data warehouses and OLAP (On Line Analytical Processing) workloads. OLTP databases are designed to handle both reads and updates, while OLAP databases are designed for read-only workloads.

OLTP databases excel at updating data in real-time and keeping it consistent in the advent of failures and concurrent accesses by means of ACID transactions. OLAP databases, on the other hand, support data loading but no ACID properties.

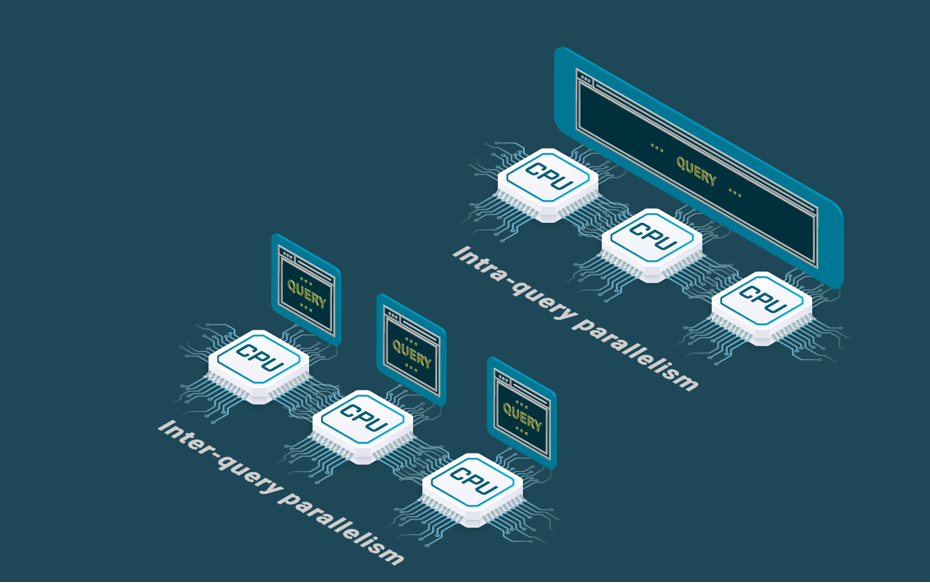
OLTP databases have a hard time answering large analytical queries. They just support inter-query parallelism to deal with OLTP workloads that consists mainly of short queries. However, OLAP databases exploit parallel processing to reduce the response times of large analytical queries in read-intensive applications. In particular, they implement intra-query intra-operator parallelism.
The two variants are complementary and data. Most organizations implement ETL (Extraction Load Transform) processes to copy data from operational databases into OLAP databases so the data can be analytically exploited in the OLAP databases.
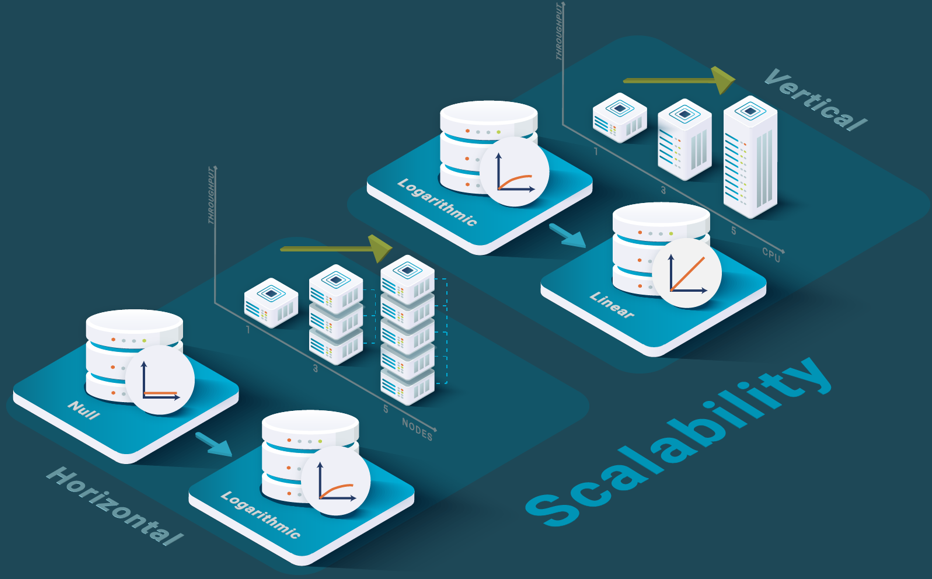
Traditional operational databases do not scale well. We can distinguish three kinds of systems with respect to scalability: databases that scale up (typically in a mainframe or database appliance) but do not scale out (see blog post on scalability); databases that scale out to a few nodes using a shared-disk architecture (see blog post on shared-nothing) and databases that scale out logarithmically for read-intensive workloads using cluster replication (see blog post on cluster replication). However, not all operational databases propose these three flavors (some are even just centralized with no horizontal scalability at all). They either do not scale out, or scale out logarithmically to low numbers of nodes. This means that the only solution is to scale up using a bigger machine. But most operational databases do not scale up well due to NUMA effects and the fact that scaling up is both very expensive in hardware (exponential growth in price) and limited by the biggest machine existing in the market at a particular time.
Traditional operational databases also have a hard time with data ingestion. The main solution to ingest large amounts of data is application-level sharding, whereby the application splits the whole database in smaller chunks and then uses different independent databases to store each of the chunks. This explicit sharding introduces a major difficulty as the database can no longer be queried as a whole. Thus, the application is forced to query the different databases independently and combine the query results, which may be very difficult for some queries, e.g. involving joins. High-rate data ingestion is also a problem, for two reasons. Firstly, updates are transactional, and transactions have a cost. Secondly, the data is typically stored in a B+ tree structure, which is efficient when querying data but inefficient when inserting/updating data when it does not fit in the memory because of I/Os per inserted/updated row.
SQL databases, whether operational or analytical, are inefficient for complex data. The rigid schema is the problem. For instance, creating a schema for rows that have optional or structured fields (like a list of items), with a fixed set of columns is difficult, and querying the data even more so. Graph data, e.g. airline and route data, is also difficult to manage. Although it can be modeled in SQL tables, graph-traversal queries may be very time consuming. For instance, finding the flights between two cities with a number of stopovers would require repeated and sparse accesses to the database (to mimic graph traversals on tables), which can be very inefficient if the graph is large.

About a decade ago, SQL databases were criticized for their “One Size Fits All” approach. Although they have been able to integrate support for all kinds of data (e.g., multimedia objects, documents) and new functions, this approach has resulted in a loss of performance, simplicity, and flexibility for applications, e.g. Web or cloud applications, with specific, tight performance requirements. Therefore, it has been argued that more specialized databases are needed.
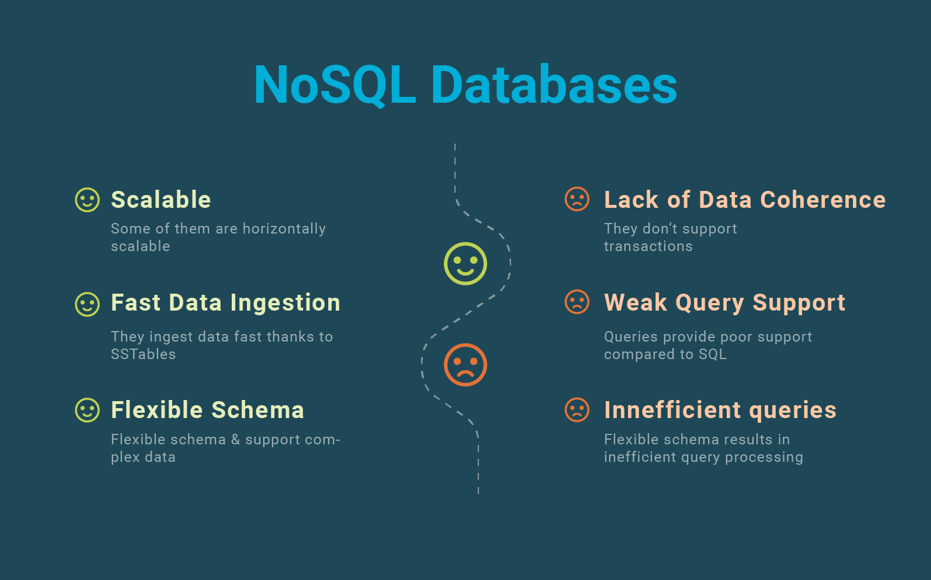
NoSQL systems (see our blog post on NoSQL) came to address the requirements of Web and cloud applications, NoSQL meaning “Not Only SQL” to contrast with the “One Size Fits All” approach of SQL databases. Another reason that has been used to motivate NoSQL is that supporting strong database consistency, as operational databases do, i.e. through ACID transactions, hurts scalability. Therefore, some NoSQL systems have relaxed strong database consistency in favor of scalability. An argument to support this approach has been the famous CAP theorem from distributed systems theory. However, the argument is simply wrong as the CAP theorem has nothing to do with database scalability: it is related to replication consistency in the presence of network partitioning (see our blog post on the CAP theorem) and not to scalability.
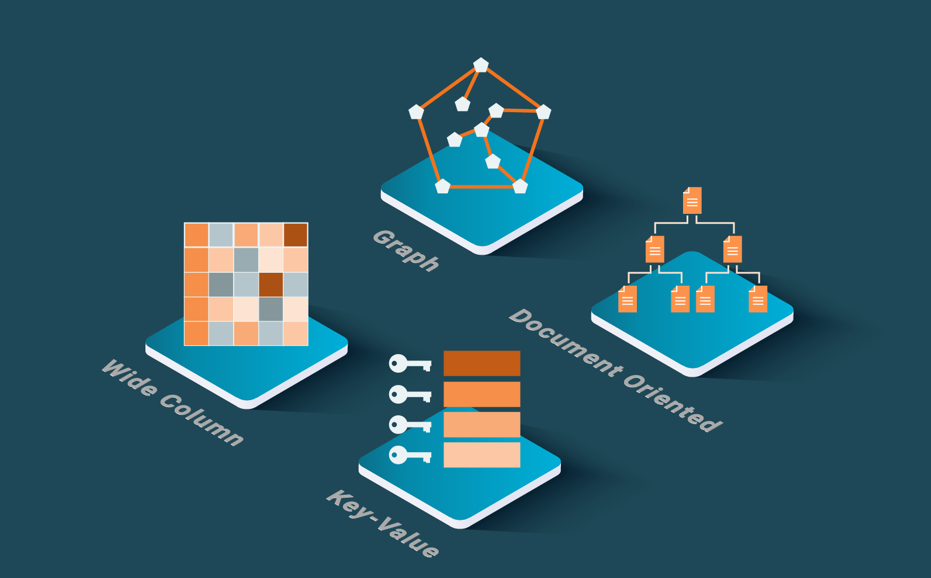
As an alternative to SQL databases, different NoSQL systems support different data models and query languages/APIs other than standard SQL. They typically emphasize one or more of the following features: scalability, fault-tolerance, availability, sometimes at the expense of consistency, flexible schemas, and practical APIs for programming complex data-intensive applications. There are four main categories of NoSQL systems [Özsu & Valduriez 2020] based on the underlying data model, i.e., key-value, wide column, document, and graph. Within each category, we can find different variations of the data model, as there is just no standard (unlike the relational data model), and different query languages or APIs. For document databases, JSON is becoming relatively standard. There are also multi-model systems, to combine multiple data models, typically document and graph, in one system. To provide scalability, NoSQL systems typically use a scale out approach in a shared-nothing cluster (see our blog post on shared-nothing).
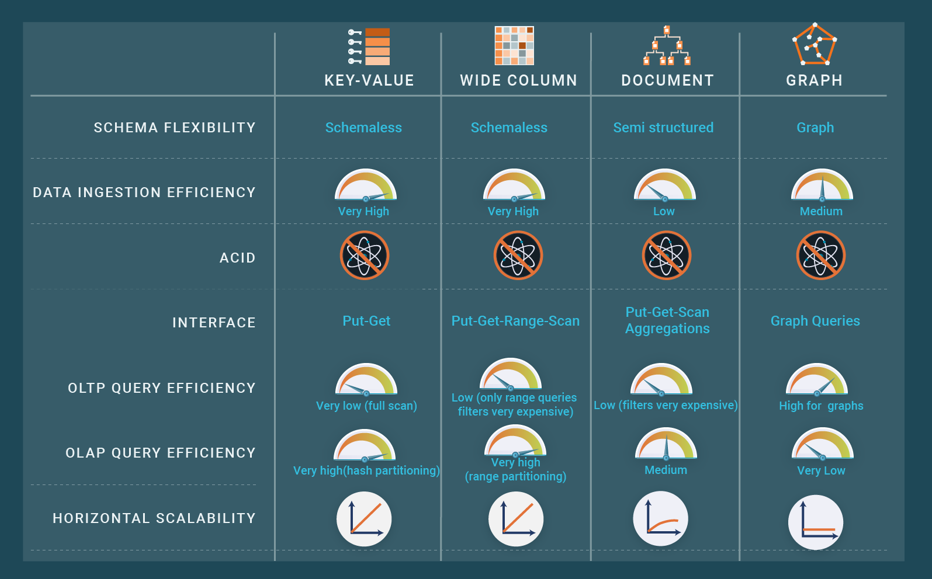
Key-value data stores are schemaless so they are totally flexible with the stored data. They are, in most cases, scalable to large number of nodes and they are very efficient at ingesting data. Wide column data stores enable vertical partitioning of the tables, while providing a key-value interface and sharing many features with key-value data stores. They provide some more functionality, such as range scans and the possibility of defining a schema. Document data stores use a flexible data representation, such as JSON or XML, and provide an API to access these data or sometimes a query language. Graph databases are specialized in storing and querying graphs efficiently. They are very efficient when the graph database can be centralized at one machine, and replicated at others. However, if the database is big and needs to be distributed and partitioned, efficiency is lost.
More recently, NewSQL movement appeared (see our blog post on NewSQL). NewSQL is a new class of databases that seeks to combine the scalability of NoSQL databases with the strong consistency and usability of SQL operational databases. The main objective is to address the requirements of enterprise information systems, which have been supported by SQL databases, but also need to be able to scale out in a shared-nothing cluster. NewSQL systems have different architectures.
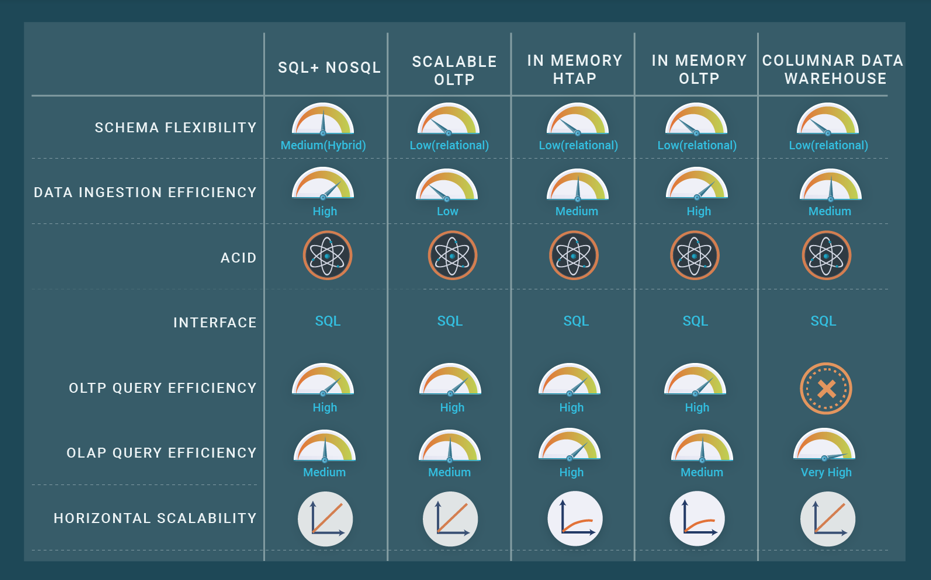
However, we can identify the following common features: support of the relational data model and standard SQL; ACID transactions; scalability using data partitioning in shared-nothing clusters; and availability using data replication. An important class of NewSQL is Hybrid Transaction and Analytics Processing (HTAP) whose objective is to perform OLAP and OLTP on the same data. HTAP allows performing real-time analysis on operational data, thus avoiding the traditional separation between operational database and data warehouse and the complexity of dealing with ETL.

Main takeaways
SQL databases and their two variants, operational and analytical, have been around for more than three decades. But their “One Size Fits All” approach has resulted in a loss of performance, simplicity, and flexibility for specific applications, e.g. Web or cloud applications.
NoSQL systems came to address the limitations of SQL databases, with different data models (key-value, wide column, document, and graph), and by relaxed database consistency in favor of scalability.
More recently, NewSQL came up to combine the scalability of NoSQL databases with the strong consistency and usability of SQL operational databases.
References

[Özsu & Valduriez 2020] Tamer Özsu, Patrick Valduriez. Principles of Distributed Database Systems, 4th Edition, Springer, 2020.
Relevant posts from the blog




ABOUT THIS BLOG SERIES
This blog series aims at educating database practitioners in topics commonly not well understood, often due to false or confusing marketing messages. The blog provides the foundations and tools to let the reader actually evaluate database systems, learn their real capabilities and be able to compare the performance of the different alternatives for its targeted workload. The blog is vendor agnostic.
ABOUT THE AUTHORS
- Dr. Ricardo Jimenez-Peris is the CEO and founder of LeanXcale. Before founding LeanXcale, he was for over 25 years a researcher in distributed databases director of the Distributed Systems Lab and university professor teaching distributed systems.
- Dr. Patrick Valduriez is a researcher at INRIA, co-author of the book “Principles of Distributed Databases” that has educated legions of students and engineers in this field and more recently, Scientific Advisor of LeanXcale.
ABOUT LEANXCALE
LeanXcale is a startup making a NewSQL database. Since the blog is vendor agnostic, we do not talk about LeanXcale itself. Readers interested in LeanXcale can visit the LeanXcale website.