
NewSQL is the latest technological development within the big data management landscape that is enjoying a fast growth rate in the DBMS and BI markets. NewSQL combines the scalability and availability of NoSQL with the consistency and usability of SQL. Through the delivery of online analytics over operational data, NewSQL opens new opportunities across many application domains where real-time decisions are critical. Example use cases include online advertising, proximity marketing, real-time pricing, risk monitoring, and real-time fraud detection. NewSQL can simplify data management by removing the traditional separation between operational databases, data warehouses, and data lakes. In other words, no more ETLs!
A remaining challenge is scaling out transactions in mixed operational and analytical (Hybrid Transactional Analytical Processing or HTAP) workloads over big data, which could originate from multiple data stores (e.g., HDFS, SQL, NoSQL). Today, only a few NewSQL systems have solved this problem. Multiple approaches with various architectures and features can achieve the goals of NewSQL.
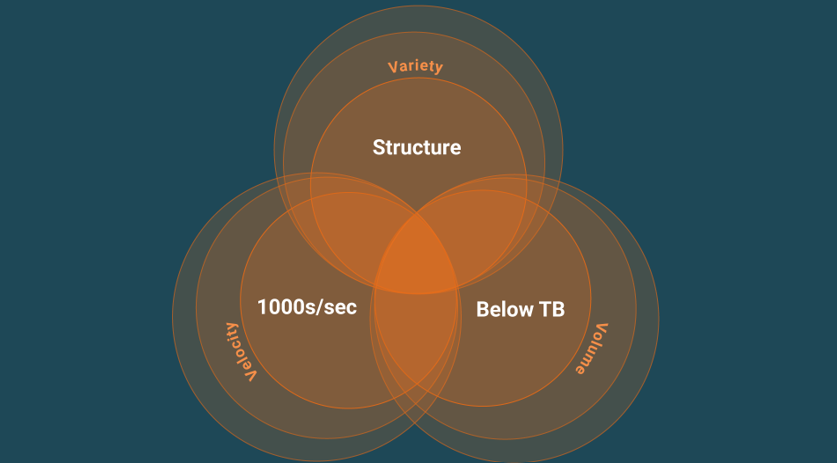
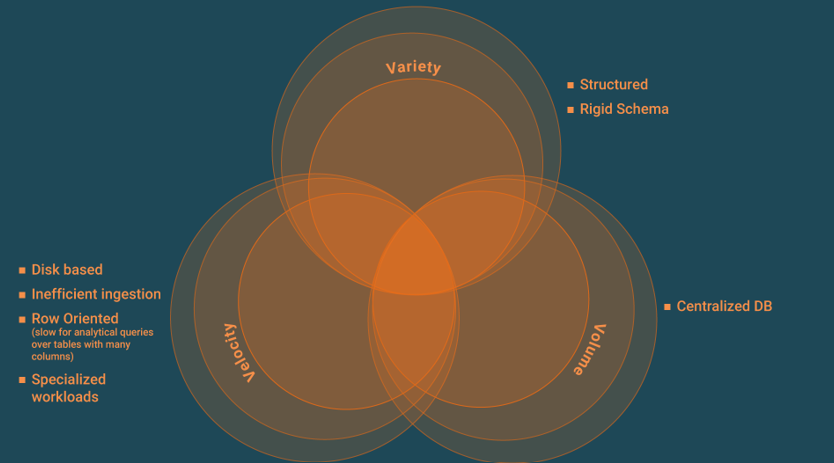
In [Jiménez-Peris & Valduriez 2019], we propose a taxonomy of NewSQL systems. Before introducing this taxonomy, we review here the key limitations of traditional SQL that are overcome with NewSQL and describe these through the famous three big Vs (Volume, Velocity, and Variety) often applied for characterizing big data (see Figure 1). Today, more Vs have been identified, such as Veracity and Validity, so the common characterization has lost its focus. Volume and Velocity are interrelated because any increase in volume impacts velocity, such that the higher the volume, the lower the velocity. This volume limitation is correlated to a centralized database manager or its lack of scalability. Velocity captures the limitations related to the efficiency of the database processing, such as slow transactions, slow data ingestion, and slow query processing. An informal characterization might be stated as a Velocity below 1000s units/second, where a unit is a transaction, query, or read/write operation and Volume is up to 100s of GB, but below 1 TB. As a final example, schema rigidity and lack of support for complex data are captured by the Variety dimension and characterized by the structured schema in traditional SQL.
SQL databases are designed as either operational or analytical, which are two approaches that have existed for more than three decades, as described in [Özsu & Valduriez 2020]. Operational databases focus on OLTP workloads and excel at updating data in real-time and keeping consistency to safeguard against failures while enabling concurrent access for ACID transactions. However, this architecture is challenged in answering large analytical queries. On the other hand, analytical databases are specialized for data warehouses and OLAP workloads by exploiting parallel processing to speed up analytical queries reading billions of rows (see our blog post on scalability for the definition of speed up and scalability).
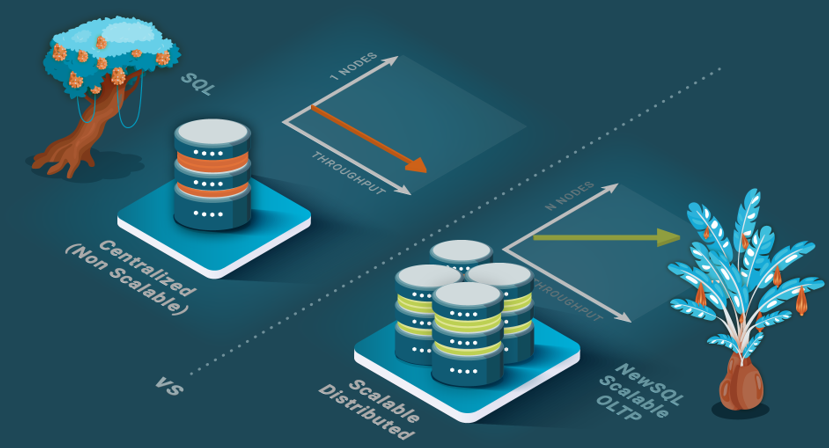
Why do we define this separation between operational and analytical when both OLTP and OLAP workloads are needed by most organizations? Supporting both features within a single database system is very hard, and performing well with one workload type introduces tradeoffs that hamper capabilities to support the other. Therefore, operational and analytical databases each feature exclusive limitations while also sharing a common limitation, rigid schema, and an inability to process unstructured, semi-structured, or complex data. NoSQL addresses all these limitations. Operational databases lack horizontal scalability and inefficiently ingest data (see Figure 2). Without horizontal scalability, in a shared-nothing cluster (see our blog post on shared-nothing), a few challenges exist. First, ACID transactions rely on either a centralized transaction manager that creates a single node bottleneck or independent transaction managers that coordinate using an agreement protocol called two-phase-commit (2PC). However, 2PC is a centralized protocol that creates contention and restricts significant scalability. Second, how many queries can be handled per second is limited by the performance of a single node. Third, the quantity of data that can be stored cost-effectively is limited. Storing large data volumes in a traditional operational database is very expensive because of inefficient data ingestion that results from the B+ tree data structure for organizing data. While a B+ tree is efficient for querying data, the algorithm is inefficient for large insert/update queries that cannot fit in memory because of the I/O operations required per inserted or updated row. This approach creates significant overhead in data ingestion because all updates must be done through such expensive transactions.
The two SQL variants described above are complementary and established the traditional separation between operational databases for OLTP and informational databases/data warehouses for OLAP. Therefore, data from operational databases must be uploaded to and pre-processed first within the data warehouse so that it can be queried. Additional problems emerge from the difficulties and costs of managing multiple databases synchronized with ETLs. First, analytical databases cannot perform updates, resulting in analytical queries returning stale data, say from the previous day. This synchronicity issue introduces another technical complication of scheduling loading and querying data because available times for data loads may be sufficiently restricted that the data warehouse can no longer fulfill the organization’s requirements.
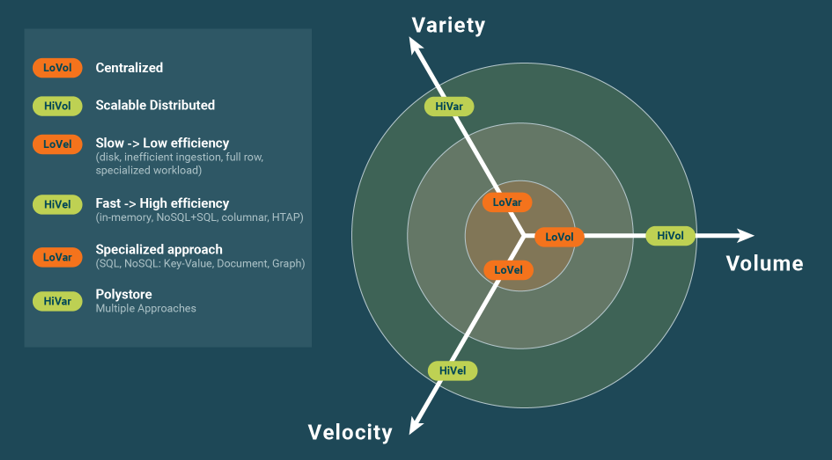
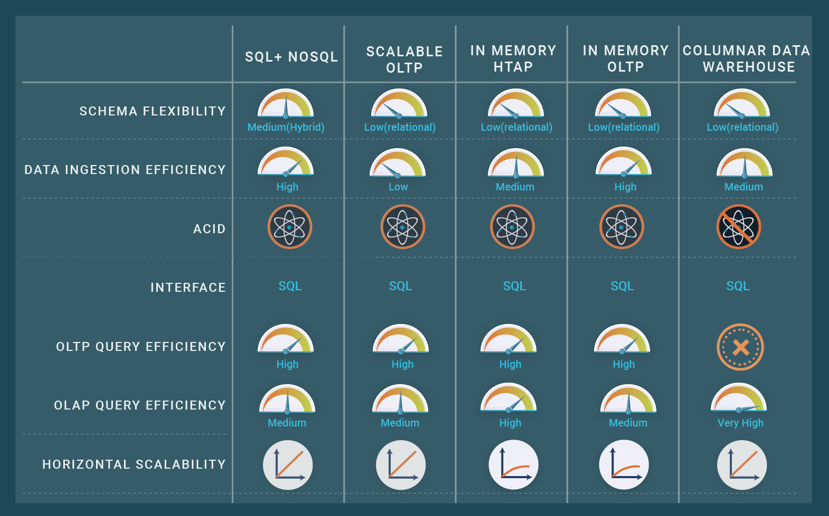
NewSQL systems are available in various flavors, each targeted at specific workloads and usages. The taxonomy described in [Jiménez-Peris & Valduriez 2019] helps understand NewSQL systems based on the dimensions of targeted workloads (OLTP, OLAP, HTAP), features, and implementation techniques. The following introduces the primary features available with NewSQL of scalable ACID transactions, in-memory, column-oriented, vertically partitioned, polystore, and HTAP, each of which can be mapped to the 3 Vs of big data. NewSQL systems typically support more than one of these features but are often characterized by the singular feature at which it excels, such as in-memory databases. Some of these systems with multiple features have existed long before coining the term NewSQL, e.g., in-memory databases or column-oriented data warehouses. In this post, we pragmatically focus on explaining and classifying existing NewSQL technology using the strictest version of the term, as in [Özsu & Valduriez 2020], where only scalable ACID transactions and HTAP fit the definition. Scalable ACID transactions are provided for big OLTP workloads using a distributed transaction manager that can scale to many nodes. ACID properties of the transactions are fully provided, with isolation levels including serializability or snapshot isolation. The few systems that solved this hard problem address both the Velocity and Volume dimensions of big data. The horizontal scalability of the ACID transactions supports the velocity in terms of transactions per second processed and enables the storage of large volumes of data, typically on top of a key-value store.
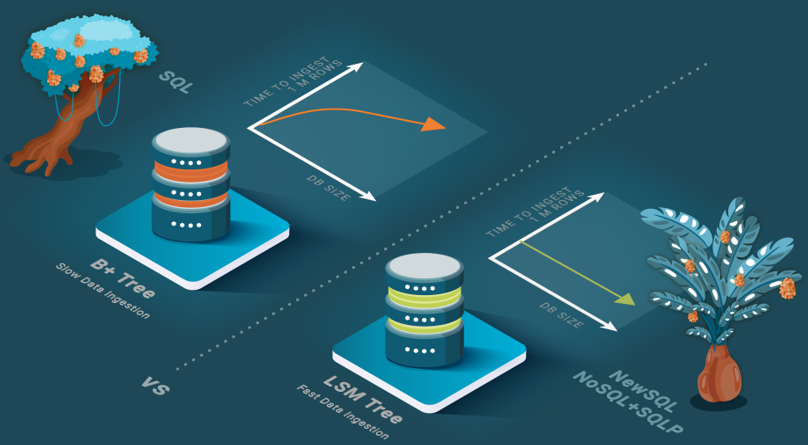
Some NewSQL databases are highly efficient at ingesting data due to the introduction of architectural elements inspired by NoSQL databases, such as key-value data stores. Other NewSQL databases rely on LSM trees algorithms that can ingest data one to two orders of magnitude faster than traditional SQL databases based on B+ trees, which store data on leaf nodes that typically do not fit in the block cache requiring a read for each row to access the leaf node from the disk followed by a write. On the other hand, LSM trees maintain updates in a cache that is propagated periodically to the B+ tree, enabling multiple updates per leaf node of the B+ tree that amortizes the read/write of the leaf block across many rows.
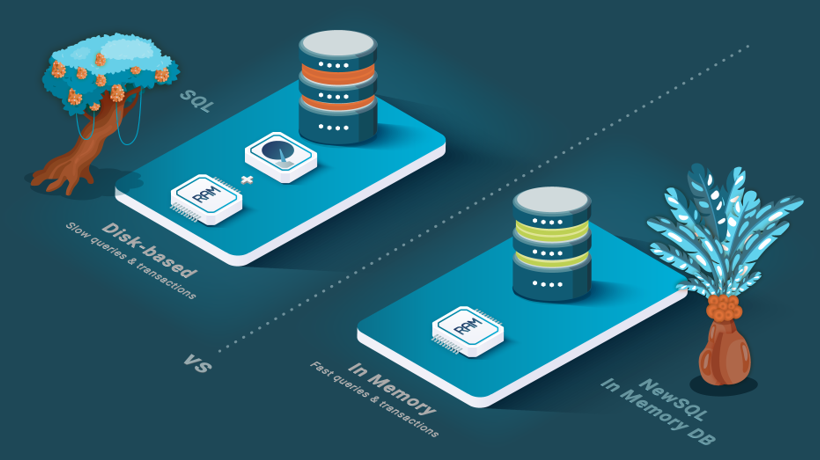
In-memory database solutions, available as analytical or operational, focus on the Velocity dimension of big data by keeping all data in memory. This architecture enables processing queries at the speed of memory without limitations caused by I/O bandwidth and latency. The in-memory analytical databases are very fast but carry two limitations. First, the entire database and all intermediate results must fit into the available memory, which makes it unpredictable if queries evolve. Second, if the database is centralized, then its capacity is limited to one node, or if it is distributed, then the network bandwidth limits performance. A few operational databases are in-memory that leverage diverse approaches. For example, one approach processes short transactions sequentially to achieve high throughputs in a centralized setting. Another approach provides an in-memory hash table that conveniently stores and accesses data through a key-value interface.
Column-oriented databases are further distinguished as column-oriented storage and column-oriented query processing. Column-oriented storage offers two key benefits. First, storing per column enables the application of multiple data compression techniques efficiently, such as run-length-encoding and max-min pruning. The second benefit is that when processing a query requiring several columns (say, five) from a table containing many columns (say, 100), and the result must scan many rows, 95% of the I/O bandwidth and memory utilization is saved by only reading the five columns and maintaining these in memory. On the other hand, with row-oriented storage, as is performed by most SQL databases, all 100 columns move from disk to memory, consuming 20 times more I/O bandwidth and 20 times more memory during caching in memory before processing.
Column-oriented query processing takes an additional step by maintaining intermediate results in the column-oriented format. This technique, called late row materialization, enables very fast query processing for some queries that fit well into this model. A shortcoming of column-oriented databases is that, at some execution step, such as producing the result, the rows should be materialized, which requires expensive join operations. Column-oriented databases focus on the Velocity dimension of large analytical queries, although the data compression capability addresses, to some extent, the Volume dimension.

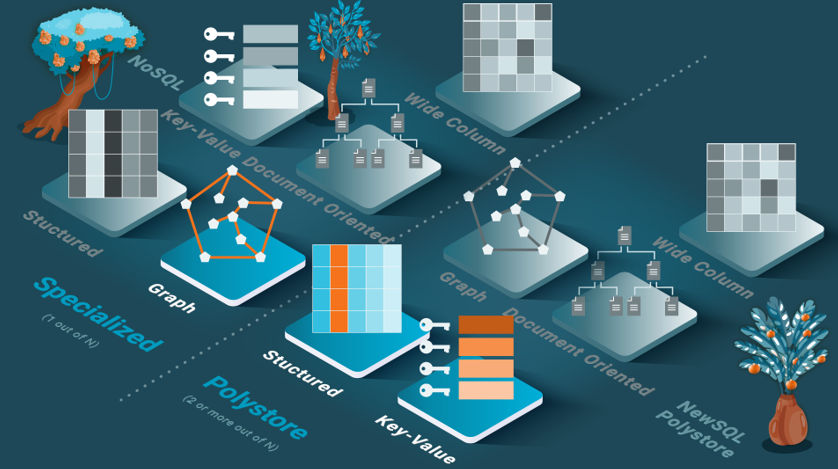
Vertically partitioned databases focus on the Velocity dimension for analytical queries and represent an intermediate class between column-oriented and row-oriented databases. These partition the columns into multiple subsets that collectively represent a full coverage of the complete set of columns. Each vertical partition stores the primary key and subset of columns. This approach is adopted by one NewSQL data warehouse and is well-known in distributed databases (called vertical fragmentation in [Özsu & Valduriez 2020]). Some of the same benefits of column-oriented storage are available, including saving the movement of many unneeded columns without materializing rows. This type of data warehouse performs well when the analytical queries are static and known a priori, for which a good vertical partitioning scheme can be designed. Limitations exist in that many columns (in addition to the primary key) are repeated across many vertical partitions, thus occupying more space. Whenever the analytical queries change, the vertical partitioning must be redesigned. This requirement drives its primary limitation that ad hoc queries, which are unknown a priori, may have high execution time. Polystores, also called multistore systems, provide integrated access to various data stores, both SQL and NoSQL, through one or more query languages. These typically support only read-only queries, as distributed transactions across heterogeneous data stores are a difficult technical challenge.
Similar to database integration systems (see the Database Integration chapter in [Özsu & Valduriez 2020]), polystores use a query engine that can query multiple data stores in real-time without storing the data. They also support heterogeneous data sources, such as key-value, document, and graph data. Polystores focus on the Variety dimension of big data by enabling multiple data representations.
Hybrid Transactional Analytical Processing (HTAP) systems are databases that perform OLAP and OLTP on the same data. HTAP enables real-time analysis of operational data, thus avoiding the traditional separation between the operational database and data warehouse as well as the complexity of ETL. The HTAP technology space covers a broad spectrum. On one side, data warehouses can feature the capability to update data with ACID transactions, but only at low update rates. On the other side of the spectrum, operational databases might offer capabilities to process large analytical queries in a distributed or parallel approach, typically on top of a key-value store. However, these databases cannot provide all optimizations expected from a data warehouse, which exploit the fact that data is read-only. HTAP does not explicitly support one V dimension of big data, but it focuses on Velocity for operational and analytical workloads.
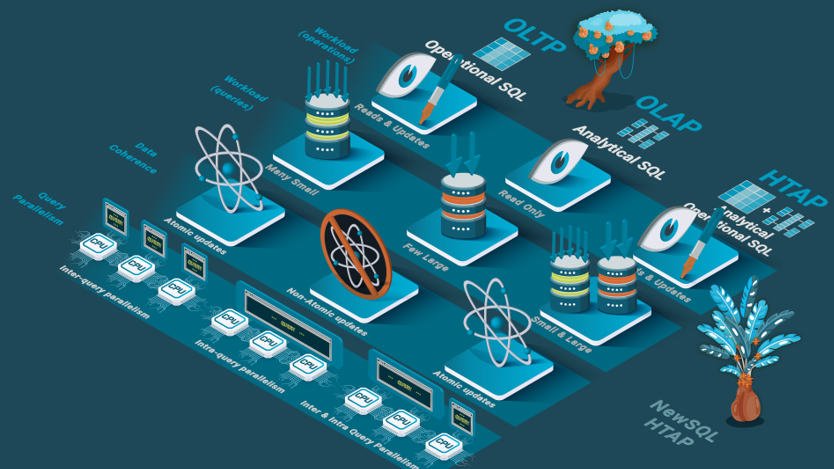
NewSQL systems can leverage one or more of the features and technologies described above, e.g., scalable operational databases that are column-oriented, HTAP databases that are in-memory and column-oriented, or, for the most advanced systems, HTAP databases with scalable transactions and polystore capabilities.
Main takeaways
NewSQL combines the scalability and availability of NoSQL with the consistency and usability of SQL.
NewSQL systems are available in multiple flavors, each targeting specific workloads and usage. These advanced databases overcome one or more limitations found in traditional SQL technologies, as expressed within the 3 Vs of big data, through new features of scalable ACID transactions, in-memory, column-oriented, vertically-partitioned, polystore, and HTAP.
NewSQL systems can leverage one or more of these technologies that best support the target workload.
References

[Jiménez-Peris & Valduriez 2019] Ricardo Jiménez-Peris, Patrick Valduriez. NewSQL: principles, systems and current trends. IEEE Int. Conf. on Big Data, 2019.

[Özsu & Valduriez 2020] Tamer Özsu, Patrick Valduriez. Principles of Distributed Database Systems, 4th Edition. Springer, 2020.
Relevant posts from the blog




ABOUT THIS BLOG SERIES
This blog series aims at educating database practitioners in topics commonly not well understood, often due to false or confusing marketing messages. The blog provides the foundations and tools to let the reader actually evaluate database systems, learn their real capabilities and be able to compare the performance of the different alternatives for its targeted workload. The blog is vendor agnostic.
ABOUT THE AUTHORS
- Dr. Ricardo Jimenez-Peris is the CEO and founder of LeanXcale. Before founding LeanXcale, he was for over 25 years a researcher in distributed databases director of the Distributed Systems Lab and university professor teaching distributed systems.
- Dr. Patrick Valduriez is a researcher at INRIA, co-author of the book “Principles of Distributed Databases” that has educated legions of students and engineers in this field and more recently, Scientific Advisor of LeanXcale.
ABOUT LEANXCALE
LeanXcale is a startup making a NewSQL database. Since the blog is vendor agnostic, we do not talk about LeanXcale itself. Readers interested in LeanXcale can visit the LeanXcale website.