

NoSQL Databases
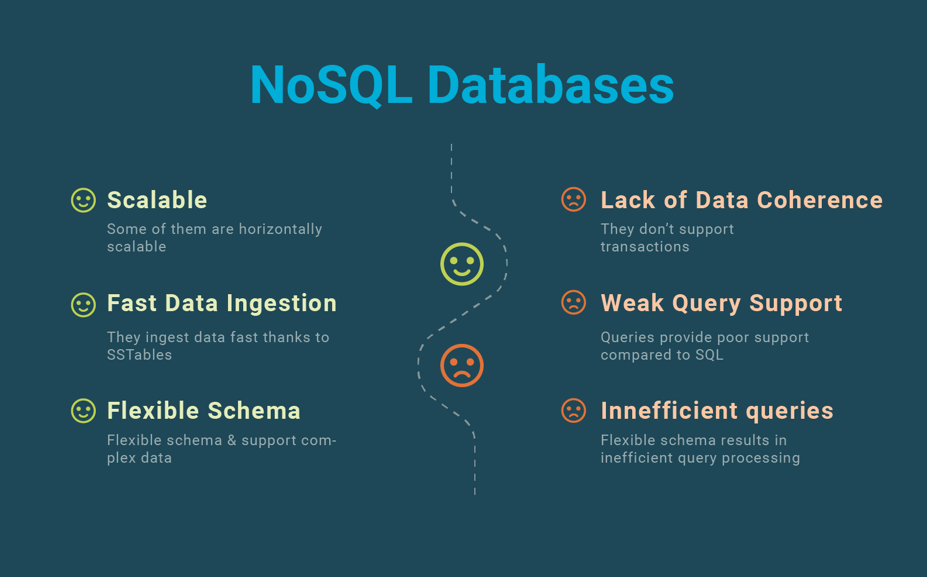
The term NoSQL, meaning “Not Only SQL”, first appeared in the late 1990s in reference to the new systems built to address the requirements of web and cloud data management and overcome the limitations of traditional SQL technology (see our blog post on SQL vs. NoSQL vs NewSQL for a comparison among different approaches). Those limitations are a lack of horizontal scalability, inefficient data ingestion, rigid schema, and difficult support of complex data such as documents and graphs.

As an alternative to traditional SQL databases, which support the standard relational model, NoSQL systems support data models and query languages other than standard SQL. They typically emphasize scalability (at the expense of consistency), flexible schemas, and practical APIs for programming complex data-intensive applications. To provide scalability, NoSQL systems typically use a scale out approach in a shared-nothing cluster (see blog post on shared-nothing) with replication for availability.
NoSQL within the Big Data Software Stack
There are four main categories of NoSQL systems (Özsu & Valduriez, 2020) based on the underlying data model, e.g., key-value data stores, wide column stores, document stores, and graph databases. Within each category, we can find different variations of the data model (unlike the standardized relational data model) and different query languages or APIs. However, for document stores, JSON is becoming the de-facto standard. There are also multi-model data stores that combine multiple data models, typically document and graph, in one system.
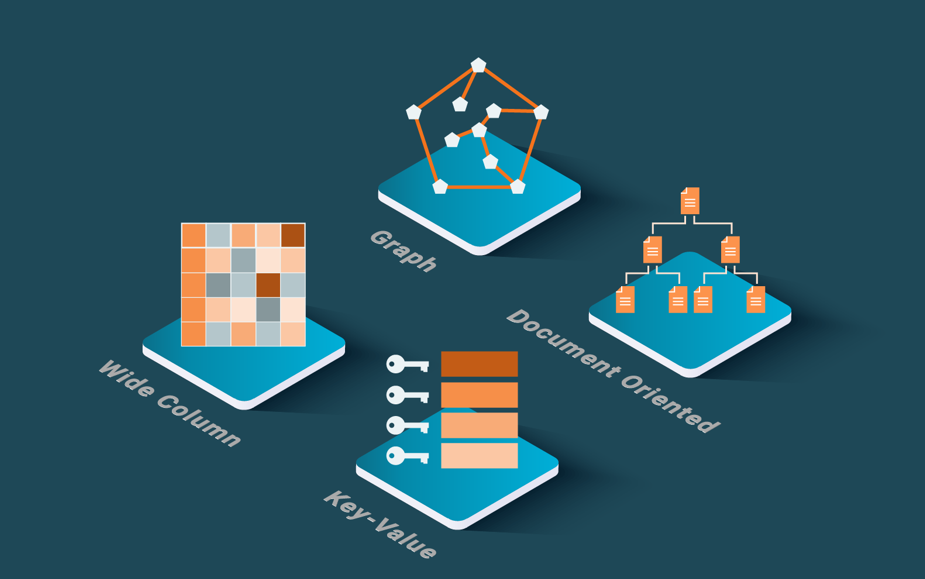
Key-Value Data Stores and Wide Column Stores
Key-value data stores and wide column stores are sometimes grouped in the same category as they both are schemaless and share many features. In the key-value data model, all data is represented as key-value pairs, where the key uniquely identifies the value. Key-value systems are schemaless, which yields great flexibility and scalability. They typically provide a simple interface such as put (key, value), value=get (key), and delete (key). Wide column stores can store rows as lists of attribute-value pairs. The first attribute is called major key or primary key, e.g., a social security number, which uniquely identifies one row among a collection of rows, e.g., people. The keys are usually sorted which enables range queries as well as ordered processing of keys. This is a capability of wide column stores that key-value stores typically don’t support.
Key-value data stores have a distributed architecture which scales out linearly in a shared-nothing cluster. The rows of a key-value collection are typically horizontally partitioned, using hashing or range on the key, and are stored over a number of cluster nodes. Key-value data stores are also good at ingesting data efficiently using SSTables (they claim to use LSM trees but actually use SSTables, see our blog post on B+ Trees, LSM trees and SSTables), a data structure and ingestion algorithm that is very efficient at ingesting data by using single I/Os to insert many rows. Key-value data stores address the rigid schema issue, simply by being schemaless, and each row can have a different structure, i.e., an arbitrary set of columns.
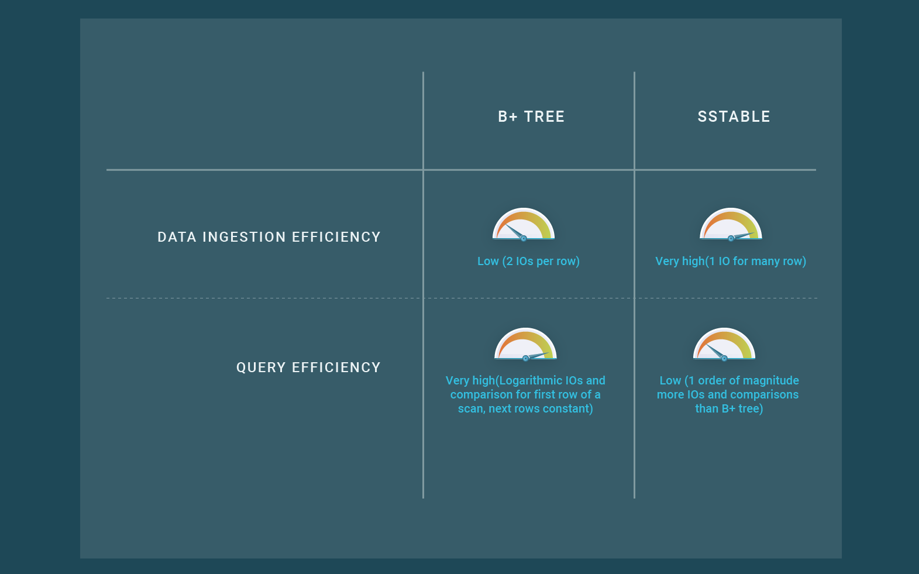
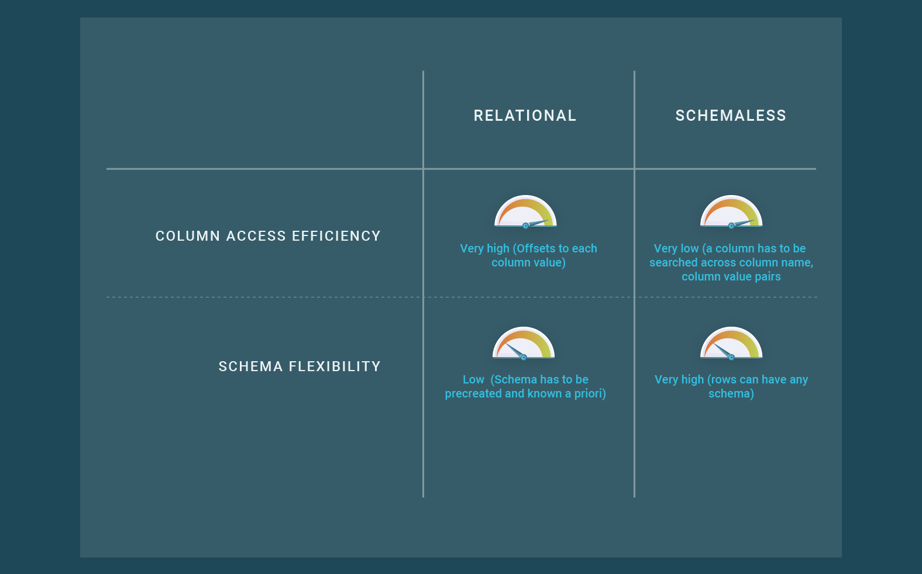
These new features of key-value data stores impact performance. First, SSTables are inefficient for querying data, so the cost of reading data in key-value data stores is much higher than in SQL databases that use B+-trees. Second, schema flexibility implies that the data representation becomes more expensive in terms of space because column names have to be coded and stored within the rows. What is more, the techniques generally used to pack columns of same sizes cannot be applied, so the data representation is more inefficient. Thanks to their fixed schema, SQL databases can organize the columns within the rows in a way that it is very efficient in terms of space and access time.
Finally, key-value stores trade strong data consistency for scalability and availability relying on different ways of controlling consistency such as eventual consistency of replicas, conditional writes, and eventually consistent and strongly consistent reads.

Wide column stores combine some of the beneficial properties of SQL databases (e.g., representing data as tables) with the flexibility (e.g., schemaless data within columns) and scalability of key-value stores. Each row in a wide column table is uniquely identified by a key and has a number of named columns. However, unlike a relational table where columns can only contain atomic values (i.e., a binary string), a column can be wide and contain multiple key-value pairs. Wide column stores extend the key-value store interface with more declarative constructs that allow scans, exact-match, and range queries over column families. They typically provide an API for these constructs to be used in a programming language.

Document Data Stores
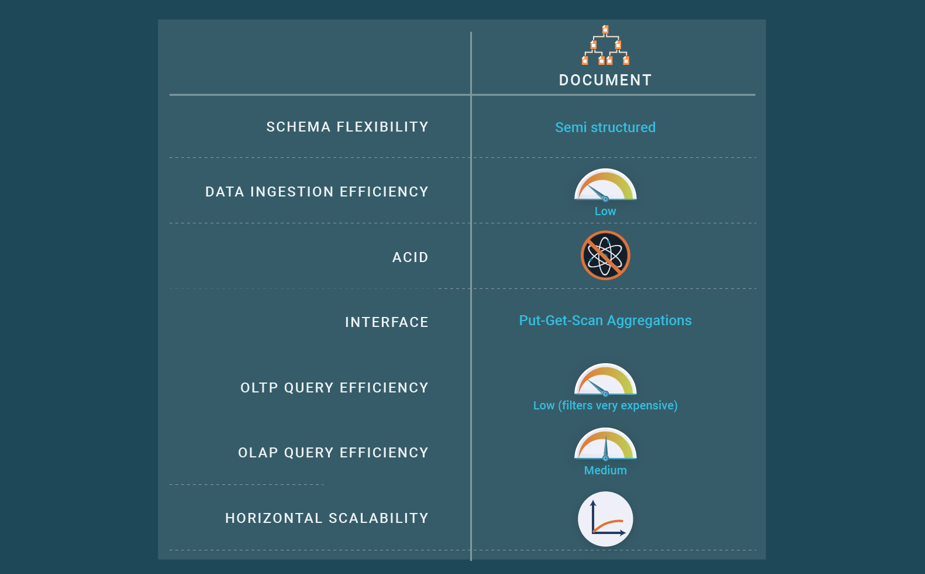
Document data stores can be seen as specialized key-value stores, where keys are mapped to values of document type, such as JSON or XML. Documents are typically grouped into collections, which play a role similar to relational tables; however, documents are different from relational rows. Documents are self-describing, storing data and metadata (e.g., field names in JSON objects) together, and can be different from other documents within a collection. Furthermore, document structures are hierarchical, using nested constructs. Thus, modeling a database using documents requires fewer collections than with (flat) relational tables and also avoids expensive join operations. In addition to the simple key-value interface to retrieve documents, document stores offer an API or query language that retrieves documents based on their contents. Document stores make it easier to deal with change and optional values and to map into program objects. This makes them attractive for modern web applications, which are subject to continual change and value deployment speed. However, schema flexibility comes at the same cost as in key-value stores, as accessing the values of specific fields makes queries expensive.
To scale out in shared-nothing clusters, documents stores support different kinds of data partitioning (or sharding) schemes: hash-based, range-based, and location-aware (whereby the user specifies key-ranges and associated nodes). High availability is provided through a variation of primary-copy replication with asynchronous update propagation (see blog post on cluster replication).
Some document stores have recently introduced support for ACID transactions on multiple documents in addition to single document transactions. This is achieved through snapshot isolation. One or more fields in a document may be written in a single transaction, including updates to multiple subdocuments and elements of an array. Multi-document transactions can be used across multiple collections, databases, documents, and shards.
Graph Databases
Graph databases represent and store data natively as graphs, which allows easy expression and fast processing of graph-like queries, e.g., computing the shortest path between two elements in the graph. This is much more efficient than with SQL where graph data need be stored as separate tables and graph-like queries require repeated, expensive join operations. Graph databases typically provide a powerful graph query language and have become popular with data-intensive, web-based applications such as social networks and recommender systems.
Graph databases can provide a flexible schema by specifying vertex and edge types with their properties. This facilitates the definition of indexes to provide fast access to vertices based on a property value, e.g., a city name, in addition to structural indexes. Graph queries can be expressed using graph operators through a specific API or a declarative query language.
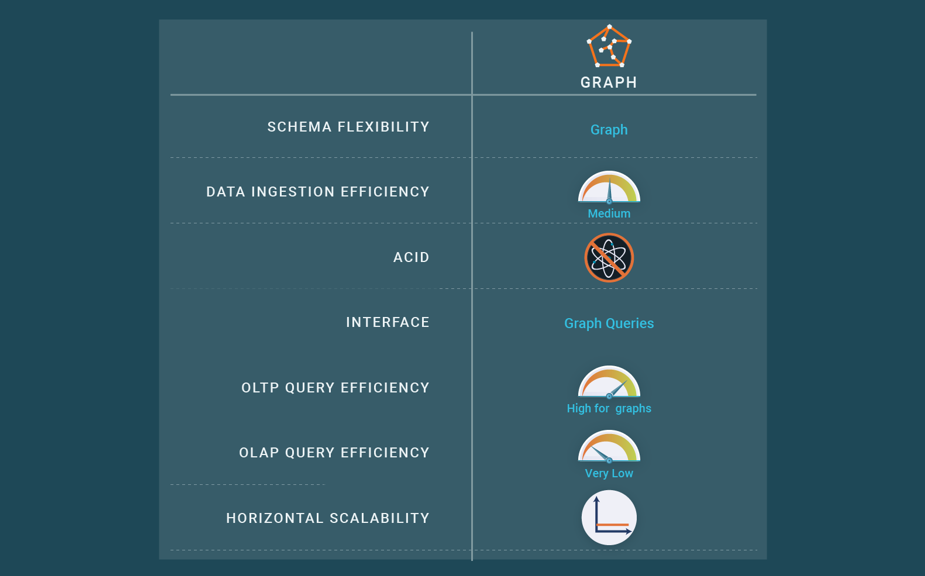
As seen above, to provide scalability, key-value, wide column, and document stores partition data across a number of cluster nodes. The reason that such data partitioning works well is that it deals with individual items. However, graph data partitioning is much more difficult since the problem of optimally partitioning a graph is NP-complete. In particular, we may get items in different partitions that are connected by edges. Traversing such inter-partition edges incurs communication overhead, which hurts the performance of graph-traversal operations. Thus, the number of inter-partition edges should be minimized; though, this may produce unbalanced partitions. Therefore, the most efficient approach is “centralized”, i.e., compacting and storing the graph at one cluster node and replicating at other nodes for high availability and read queries. In this case, it is possible to provide linear performance for path traversals while providing ACID transactions. Some graph databases allow the graph to be partitioned by using vertex-cut graph partitioning. However, graph-traversal operations may span multiple cluster nodes, hurting performance, making ACID transactions more difficult because they are distributed.
Main takeaways
NoSQL systems address the limitations of traditional SQL databases, namely, lack of horizontal scalability, inefficient data ingestion, rigid schema, and difficult support of complex data. However, they do so by selecting specific tradeoffs.
NoSQL fits in the big data software stack, in a shared-nothing cluster, and can be used in combination with big data file systems and big data processing frameworks.
Each NoSQL system brings its own new data model, e.g., key-value, wide column, document, and graph. Key-value data stores and wide column stores both provide high scalability at the expense of transactional consistency. Some document stores and graph databases provide transactions but do not scale as well.
References

[Özsu & Valduriez 2020] Tamer Özsu, Patrick Valduriez. Principles of Distributed Database Systems, 4th Edition, Springer, 2020.
Relevant posts from the blog



About this blog series
This blog series aims at educating database practitioners in topics commonly not well understood, often due to false or confusing marketing messages. The blog provides the foundations and tools to let the reader actually evaluate database systems, learn their real capabilities and be able to compare the performance of the different alternatives for its targeted workload. The blog is vendor agnostic.
About the authors
- Dr. Ricardo Jimenez-Peris is the CEO and founder of LeanXcale. Before founding LeanXcale, he was for over 25 years a researcher in distributed databases director of the Distributed Systems Lab and university professor teaching distributed systems.
- Dr. Patrick Valduriez is a researcher at INRIA, co-author of the book “Principles of Distributed Databases” that has educated legions of students and engineers in this field and more recently, Scientific Advisor of LeanXcale.
About LeanXcale
LeanXcale is a startup making a NewSQL database. Since the blog is vendor agnostic, we do not talk about LeanXcale itself. Readers interested in LeanXcale can visit the LeanXcale website.