

Shared-nothing has become the dominant parallel architecture for big data systems, such as MapReduce and Spark, analytics platforms, NoSQL databases and search engines [Özsu & Valduriez 2020]. The reason is simple: it is the only architecture that can provide scalability at reasonable cost, typically within a cluster of servers. In the context of cluster computing, scalability can be further characterized by the terms scale-up versus scale-out. Scale-up (also called vertical scaling) refers to adding more power (processor, memory, IO devices) to a server and thus gets limited by the maximum size of the server, e.g. 32 processors. Scale-out (also called horizontal scaling) refers to adding more servers, called “scale-out servers”, in a loosely coupled fashion, to scale almost infinitely.
But what does shared-nothing mean? The term was first proposed by ACM Turing Award Professor Michael Stonebraker in 1985 (the ACM Turing Award is the equivalent of the Nobel prize in Computer Science) to characterize an emerging class of parallel database systems [Stonebraker 1985]. The problem faced by conventional data management has long been known as “I/O bottleneck,” induced by high disk access time with respect to main memory access time (typically hundreds of thousands times faster) and ever growing processor speeds. Then, the solution used by parallel database systems is to increase the I/O bandwidth through parallelism; having multiple disks that can be accessed by multiple processors in parallel. Note that the main memory database system solution, that tries to maintain the entire database in main memory, is complementary rather than alternative. In particular, the “memory access bottleneck” in main memory systems can also be tackled in a similar way, using parallelism.
In a parallel database system, the real challenge is to scale linearly with increasing workloads (see our blog post on Scalability), including more users and more data. For instance, if you double the size of your cluster, you would expect to support a workload that is twice as big. For an OLAP workload, this may mean dividing the response time of a large analytical query by two, whereas for an OLTP workload this may mean doubling the system throughput (e.g., number of transactions per minute). Note that these are very different objectives, which can be achieved with different architectures and techniques. The level of difficulty to implement basic functions (concurrency control, fault-tolerance, availability, database design and tuning, load balancing, etc.) varies from one architecture to the other.
Stonebraker proposed the term “shared-nothing” to better contrast with two other popular architectures, shared-memory and shared-disk. A shared-nothing architecture is simply a distributed architecture. This means the server nodes do not share either memory or disk and have their own copy of the operating system, hence they share “nothing” other than the network to communicate with other nodes [Valduriez 2018]. In the 1980s, shared-nothing was just emerging (with pioneers like Teradata and Tandem NonStopSQL) and shared-memory was the dominant architecture.
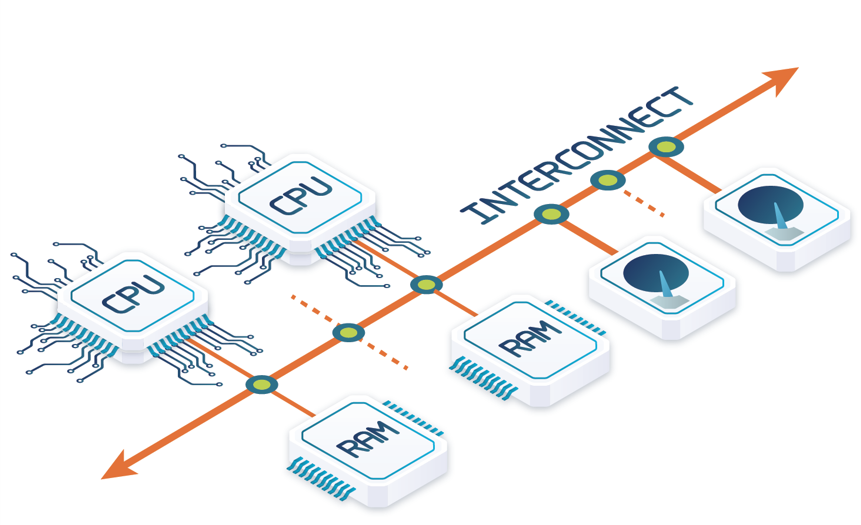
In shared-memory (see above), any processor (P) has access to any memory module (M) or disk unit through some interconnect. All the processors are under the control of a single operating system. One major advantage is simplicity of the programming model, which is based on shared virtual memory. Metadata (e.g. directory) and control data (e.g., lock tables) can be shared by all processors, which means that writing database software is not very different than for single processor computers. In particular, load balancing is easy since it can be achieved at runtime by allocating each new task to the processor with least load. However, the major problem with shared-memory is limited scalability and availability.
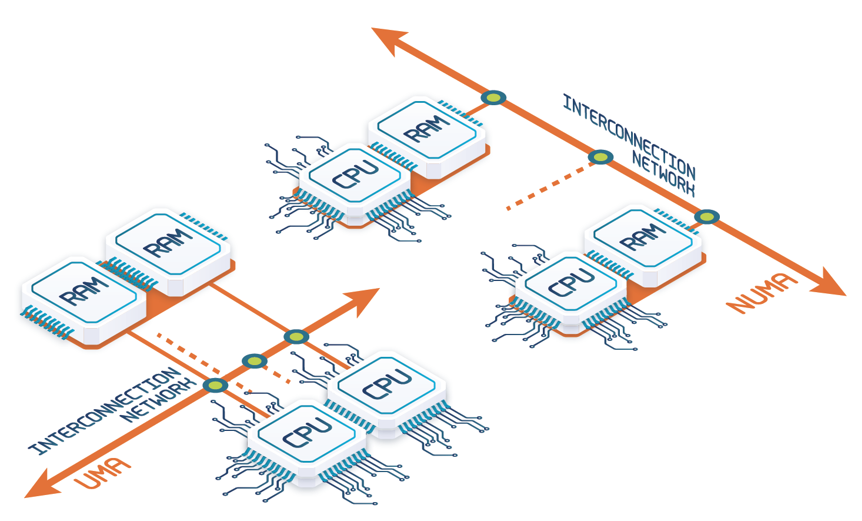
With increasingly quick processors (even with larger caches), conflicting accesses to the shared-memory increase rapidly and degrade performance. Furthermore, since the memory space is shared by all processors, a memory fault may affect most of them, thereby hurting data availability. Depending on whether physical memory is shared, two approaches are possible: Uniform Memory Access (UMA) and Non-Uniform Memory Access (NUMA) (see Figure 2). UMA is the architecture of multicore processors while NUMA is used for tightly-coupled multiprocessors. Interestingly, today’s servers are NUMA, which introduces many difficulties for database managers since they were built for UMA. In particular, seeing as all threads can access memory from an CPU, this results in a high fraction of accesses to remote NUMA memory. This results in exhausting the memory bandwidth to remote memories that is significantly smaller than the memory bandwidth of the local memory. Most database servers just do not scale up linearly in NUMA and a lot of work is needed for them to become NUMA-aware.
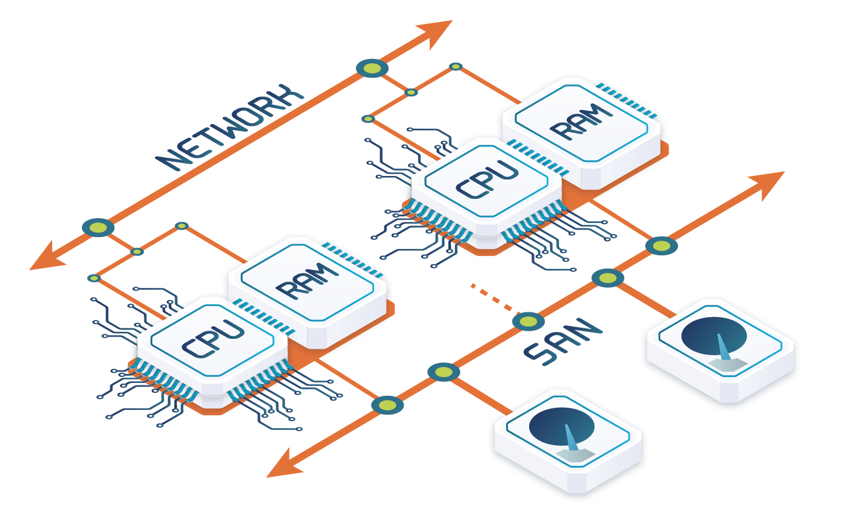
In a shared-disk architecture, any processor has access to any disk unit, but exclusive (nonshared) access to its main memory. Each processor–memory node is under the control of its own copy of the operating system and can communicate with other nodes through the network. Then, each node can access database pages on the shared-disk and cache them into its own memory. Shared-disk requires disks to be globally accessible by the nodes, which requires a storage area network (SAN) that uses a block-based protocol. Since different processors can access the same page in conflicting update modes, global cache consistency is needed. This is typically achieved using a distributed lock manager, which is complex to implement and introduces significant contention. Shared-disk has three main advantages: simple and cheap administration, high availability, and good load balance. Database administrators do not need to deal with complex data partitioning, and the failure of a node only affects its cached data, while the data on disk is still available to the other nodes. Furthermore, load balancing is easy because any request can be processed by any node. The main disadvantages are cost (because of the cost of the SAN) and limited scalability, caused by the potential bottleneck and overhead of cache coherence protocols for large databases. In the case of OLTP workloads, shared-disk has remained the preferred option as it makes load balancing easy and efficient. However, their scalability is heavily limited by the distributed locking that causes severe contention and limits the scalability to a few nodes.
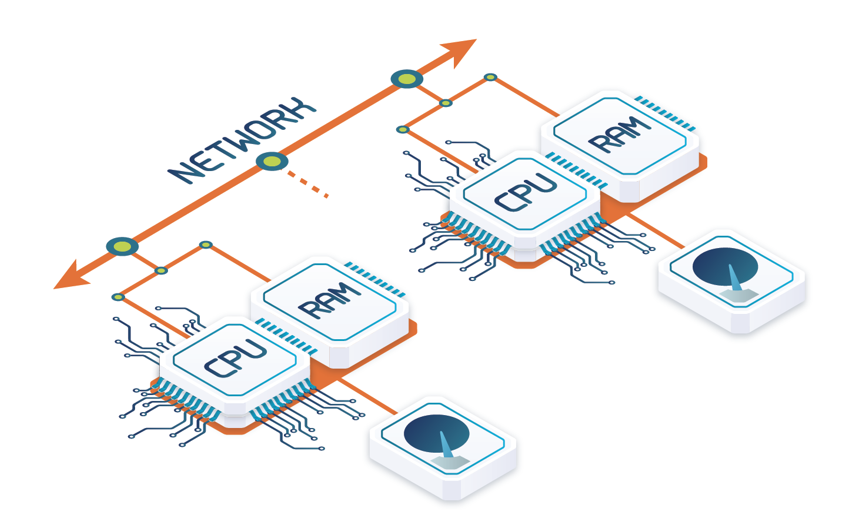
Today, a shared-nothing architecture (see Figure 4) is cost-effective as servers can be off-the-shelf components (multicore processor, memory and disk) connected by a regular Ethernet network or a low-latency network such as Infiniband or Myrinet. To maximize performance (yet at additional cost), nodes could also be NUMA multiprocessors, thus leading to a hierarchical parallel database system [Bouganim et al. 1996]. By favoring the smooth incremental growth of the system by the addition of new nodes, shared-nothing provides excellent scalability, unlike shared-memory and shared-disk. However, it requires careful partitioning of the data on multiple disk nodes. Furthermore, the addition of new nodes in the system presumably requires reorganizing and repartitioning of the database to deal with the load balancing issues. Finally, fault-tolerance is more difficult than with shared-disk, seeing as a failed node will make its data on disk unavailable, thus requiring data replication. It is due to its scalability advantage that shared-nothing has been first adopted for OLAP workloads, in particular data warehousing, as it is easier to parallelize read-only queries. For the same reason, it has been adopted for big data systems, which are typically read-intensive.
A final question is: can shared-nothing be used to support big write-intensive transactional workloads as well? NoSQL (see our blog post on NoSQL), in particular key-value systems, have excellent horizontal scalability, i.e., scaling over a cluster of nodes. However, since they did not manage to scale transactional management, they gave up on transactional consistency; choosing to focus instead on scalability. However, it is possible to provide both scalability for data management and transactional management (see our blog post on the CAP theorem). Yet, it is a hardcore problem that only a few systems in the NewSQL category have managed to solve (see our blog post on NewSQL).
Main Takeaways
There are three main parallel database architectures: shared-memory, shared-disk and shared nothing. Shared-memory is used for in-memory databases, and shared-disk for small clusters. Shared nothing is becoming the dominant technology since it works anywhere, from on-premise cluster to private or public cloud. The main challenge is to attain linear scalability and transactional (ACID) consistency. Initially, key-value NoSQL systems have been able to achieve linear scalability, but by sacrificing transactional consistency. More recently, a few NewSQL systems have been able to achieve both linear scalability and transactional consistency.
References

[Bouganim et al. 1996] Luc Bouganim, Daniela Florescu, Patrick Valduriez. Dynamic Load Balancing in Hierarchical Parallel Database Systems, Int. Conference on Very Large Data Bases, 1996.

[Özsu & Valduriez 2020] Tamer Özsu, Patrick Valduriez. Principles of Distributed Database Systems, 4th Edition. Springer, 2020.

[Stonebraker 1985] Michael Stonebraker. The Case for Shared Nothing, International Workshop on High-Performance Transaction Systems, 1985.
[Valduriez 2018] Patrick Valduriez. Shared-Nothing Architecture, Encyclopedia of Database Systems, Second Edition, Springer, 2018.
Relevant Blog Posts

ABOUT THIS BLOG SERIES
This blog series aims at educating database practitioners in topics commonly not well understood, often due to false or confusing marketing messages. The blog provides the foundations and tools to let the reader actually evaluate databases, learn their real capabilities and be able to compare the performance of the different alternatives for its targeted workload. The blog is vendor agnostic.
ABOUT THE AUTHORS
- Dr. Ricardo Jimenez-Peris is the CEO and founder of LeanXcale. Before founding LeanXcale, he was for over 25 years a researcher in distributed databases director of the Distributed Systems Lab and university professor teaching distributed systems.
- Dr. Patrick Valduriez is a researcher at INRIA, co-author of the book “Principles of Distributed Databases” that has educated legions of students and engineers in this field and more recently, Scientific Advisor of LeanXcale.
ABOUT LEANXCALE
LeanXcale is a startup making a NewSQL database. Since the blog is vendor agnostic, we do not talk about LeanXcale itself. Readers interested on LeanXcale can visit LeanXcale website.