
Introduction
Technological growth is constantly modifying the way in which business is conducted. The ease with which enormous volumes of data are collected, stored and processed is allowing old-fashioned, corporate companies to become agile and high-performing. This transformation can even impact upon traditional, organizational culture. Companies have to modify the way in which they make decisions. When it comes to determining decision making, data and models have taken over from intuition, experience or the actions of competitors.
Although this technical evolution is a horizontal trend, it is having a defined impact upon verticals such as banking, insurance and financial services. These companies are using all their data assets when improving their portfolio, increasing their quality of service and enhancing their ability to make smart decisions in their data pipelines.
Often, the typical behaviour of a financial corporation department is based on the availability of some processed data that is the outcome of a long data pipeline. Making these data pipelines more agile will impact upon the performance and the satisfaction of the whole corporation – something upon which technical executives often focus.
Data pipelines
Traditionally, data architectures are divided into two main parts: Operational and Analytical. Analytical data stacks are often considered as merely the data warehouse. However, most organizations have an abundance of data pipelines in which they collect and transform data into a usable form. These data pipelines have to deal with a constantly increasing volume of data.
The development and maintenance of these processes makes up a large proportion of the expenses of an average IT corporation. McKinsey indicates that a midsize institution with $5 billion of operating costs spends more than $250 million on these kind of data architectures.
As can be seen, these data pipelines are a key element within the functionality of most banking and insurance departments.
Challenges
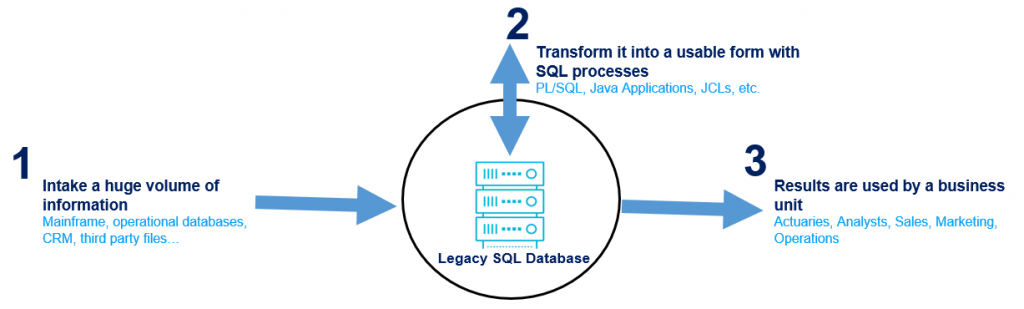
Data pipelines need to collect information from different sources, transforming it into a format whose use allows an end-user to make decisions within a specific time window.
Data pipelines are frequently based on legacy code which uses SQL databases. However, only a limited velocity can be provided by this kind of data architecture. Due to an increasing demand within organizations for the processing of large volumes of data, more data pipelines are lasting more than half the time window.
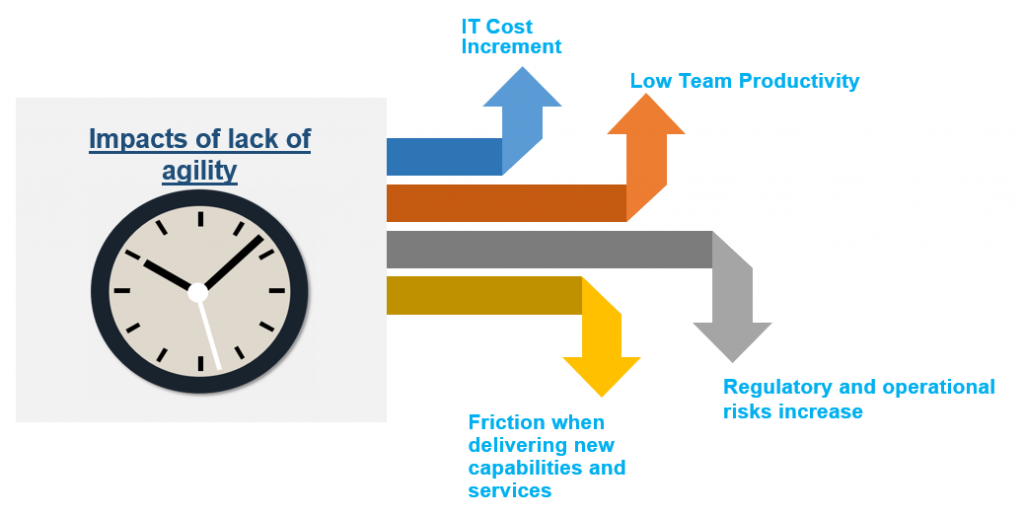
This lack of agility for a regular data pipeline is an extremely common situation that tends to generate four types of issue:
- Increase in IT costs: Generally speaking, infrastructure and support costs are linearly proportional to the duration of the process. This fact is especially evident in a cloud environment where the payment is per resource usage. This is to say that the longer the process, the higher the invoice figures.
- Low productivity teams: Actuaries, analysts or simply employees from other departments, spend more time waiting for the processed data to become available than they do applying it. Waiting periods such as this severely reduce the productivity of those members of staff.
- Increase in regulatory and operational risks: Data pipelines must be executed within a certain period of time. However, when the duration of the data pipeline is longer than half of the time window, if an unexpected issue occurs, the process cannot be completed within the available time window. Where there is a dependence upon some of these processes within an organization, the business can become erratic and unpredictable. This creates untold hassle and discomfort among the management.
- Friction when delivering new capabilities and services: Product teams detect new business opportunities, meanwhile other departments detect ways to improve their performance. However, these things are often unable to be implemented due to the current technology’s lack of processing agility.
How can data pipelines be accelerated?
As discussed, the execution time of these data pipelines is very often limited by the underlying database performance. Migrating to a different database is the most direct way of speeding-up these processes.
For example, LeanXcale is a relational database that provides high-rate ingestion capacity and linear horizontal scalability. It is an optimal database for finance and insurance companies and fixes the problems outlined in the above paragraphs.
LeanXcale can intake data with the speed of a key-value store, independently of the volume of already stored data. In short, it is efficient for the first million rows, but also when working with thousands of billions of rows.
LeanXcale allows parallel reading and writing, with high efficiency. It provides an exclusive patent-pending technology that allows any type of aggregates in ingestion time to be computed without conflict or contention. For example, a broker can compute, in real-time, the positions taken by customers, in order to avoid excessive leverage and the risk of a flash crash.
It is out-of-the-box integrable with main corporate software (i.e., ETL, BI, Spark or Kafka) and with the in-house application, since it provides JDBC and ODBC drivers and connectivity for applications written in C, Java, .Net, Python, NodeJS, etc.
LeanXcale can scale horizontally in a linear manner. Standard relational databases either do not scale-out at all, or they do so logarithmically, meaning that two nodes provide less performance that two times a single node. The third node provides less performance than the second and so on. Thus, the cost increases exponentially. LeanXcale with 100 nodes delivers 100 times the performance of a single node. That is, LeanXcale’s performance is linearly proportional to the number of cores, independent of the number of servers on which it is running.
Why use LeanXcale?
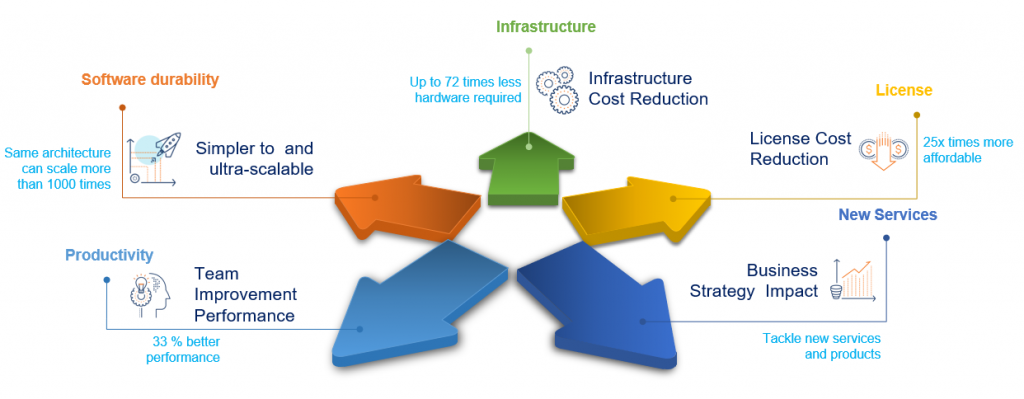
The main benefits that LeanXcale provides are:
- Sped-up data processing: Fundamentally, LeanXcale’s performance reduces processing time. For example, this customer’s processing for computing credit scoring companies, it proves to be 72 times faster than the market leader:
- Customizable speed-up: Since speed is proportional to the total number of cores, LeanXcale allows for acceleration, without cost, in pay-per-use environments – if a server lasts 10 hours, 10 servers will need just one hour to execute the same process.
- Low TCO: LeanXcale’s performance, along with its licensing model, results in more affordable ownership.
- Long cycle development amortization: Thanks to its linear scalability, LeanXcale is prepared to take on any scale, meaning that applications have a longer life span, not limited by the scalability of the database. Other relational databases incur an exponential cost increase when increasing the number of nodes. LeanXcale has the same cost per transaction, independent of the number of nodes being used.
- Easy to migrate: Easy to reuse legacy SQL logic. Ready for corporate environments. JDBC and ODBC connectivity, Kafka, Spark, R o Tensor-flow integrations.
- Avoid cloud vendor-lock: LeanXcale can be executed on-premise, on VM, on containers or on any cloud-provider.
- Enable new use cases: LeanXcale can be used in real-time processing scenarios without limiting the ingestion rate or the amount of processing.
Accelerating processes. When is it useful and how does it benefit an organization?
Insurance, banking and financial service companies are plenty of data pipelines that are used to solve different use cases. Some examples are:
Risk Processing
- Problem: Simply put, finance and insurance companies have to process a lot of information from different sources in a short window of time. They do so in order to estimate the risk they are taking, so that they can be sure to have enough reserved capital in case any unexpected situations were to arise.
- The benefit of LeanXcale: Capacity to process more information in less time, therefore improving the risk forecast.
- The value of LeanXcale: Since the data pipeline can process all the available information, thus increasing the precision of the forecast, the company requires less capital to cover the risk. This fact may dramatically increase the company’s profitability.
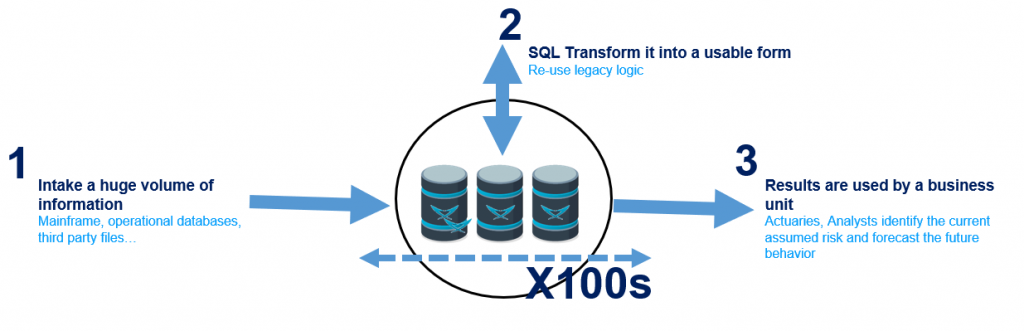
Credit Scoring
- Problem: Finance and surety insurance organizations must estimate the creditworthiness of persons and organizations to determine whether to give or deny credit. Usually, they process the information in batches, meaning that there are “blind” time-windows with no processed information. These batches are heavy and cause companies to trade-off between higher batch process frequencies with no operational database impact, and the risk of not completing the process within the time-window.
- LeanXcale benefit: Capacity to process a greater volume of information in less time, even in real-time.
- LeanXcale value: Since more information can be processed in a shorter amount of time, the information considered is fresher and therefore more accurate and valuable. This enables the reduction of the average default rate and therefore increases profitability.
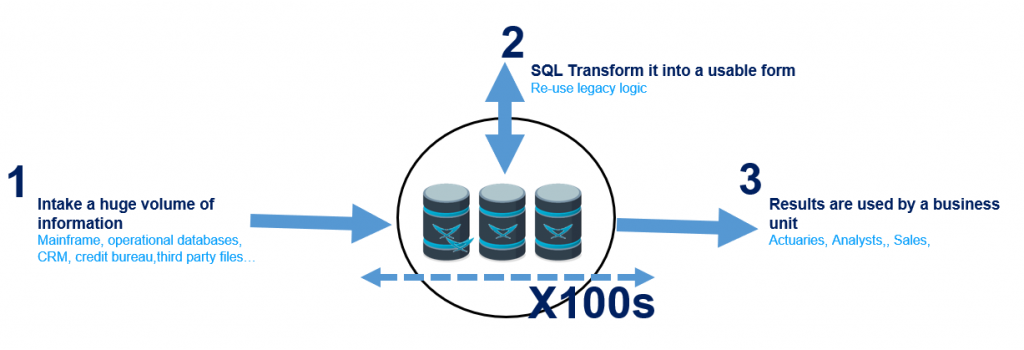
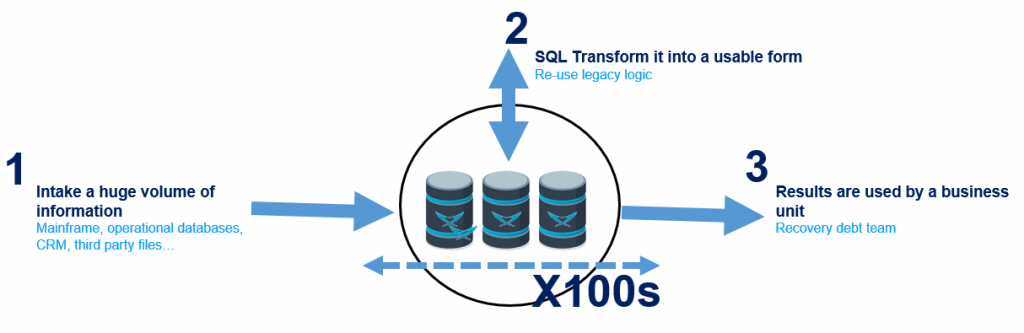
Debt Management
- Problem: Financial services must recover customer debt. They pre-process the debt information in batches and use different media for its recovery – e.g., phone calls, SMS, e-mail. The longer the processing time, the shorter the recovery time. Additionally, they compute KPIs in order to optimise the recovery team’s performance.
- The benefit of LeanXcale: Real-time KPIs to optimize the recovery team (e.g., deciding when to switch a team person from phone calling to training).
- The value of LeanXcale: Boost the performance and the efficiency of the recovery team.
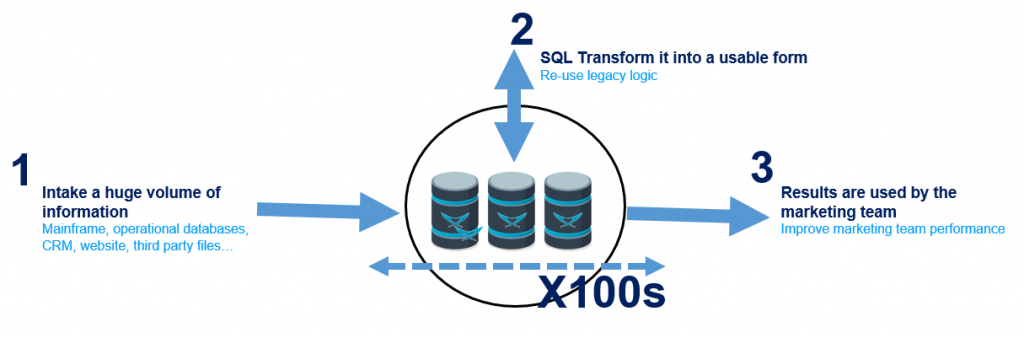
Marketing
- Problem: Companies optimize their marketing campaigns with all the available information to segment, identify “in-market” profiles and personalize messages and offers. If the process is long (e.g., days), companies spend a fraction of the time running sub-optimal campaigns (e.g., 10 days delay in a monthly process means 1/3 of the marketing is done with obsolete data).
- The benefit of LeanXcale: Marketing and business can run optimal marketing campaigns with the available data.
- The value of LeanXcale: Reduce the Customer Acquisition Cost (CAC).
Speeding-up a data pipeline. How does it benefit an organization?
Transforming a data pipeline is a low-risk project, since batch processes can be executed as many times as required and can easily run in parallel with the previous versions.
If the new database for the process is an SQL database, like LeanXcale, the migration process is simpler. This is down to the fact that the process can re-use the legacy SQL code and may require only some minor changes.
If the process is sped-up, the corporation will find itself with a more predictive behaviour (the periodic process will not fail due to issues preventing its completion in the available time window), something which will naturally benefit the IT department – enhancing their reputation whilst removing inter-departmental friction.
Additionally, in the case of LeanXcale, the total cost of ownership is reduced due to its superior performance (requiring less hardware resources) and licensing (less expensive). Thanks to LeanXcale’s ability to scale-out from one node up to hundreds of nodes, the platform will be prepared for any future growth and the development investment will have a much longer amortization cycle.
These benefits will have a daily impact upon any organization. A technical executive that oversees this transformation will increase their visibility through increasing the reliability of the company, whilst solving well-known problems that impact other units.
Additionally, they will tackle new ways to create revenue streams, allowing the creation of new services that require real-time or shorter processing times.
Moreover, their image will be shaped into that of a technology leader, expert, and visionary, due to the overwhelmingly positive impact that the use of technology will have on the company’s KPIs.
Conclusions
Competition is pushing banking, insurance, and financial services companies to make decisions based on data. However, these companies rely on data pipelines that are not agile enough to keep up with the competition.
Excessively long processes make corporations disjointed, creating a lot of noise and disagreement. Technical executives are forced to accelerate them in order to reduce the operational risk and to tackle new services and products.
LeanXcale is an optimal database that can play an integral role in this journey due to its combination of high-rate ingestion, easy-to-use SQL, and linear scalability. This means that LeanXcale can accelerate data pipelines by several orders of magnitude with a low TCO and a long amortization cycle. This acceleration will dramatically impact the overall performance of the company, providing a marked competitive advantage over other businesses.
ABOUT THE AUTHOR
- Dr. Ricardo Jimenez-Peris is the CEO and founder of LeanXcale. Before founding LeanXcale, for over 25 years he was a researcher in distributed database systems, director of the Distributed Systems Lab and a university professor teaching distributed systems.
- Mr. Juan Mahillo is the CRO of LeanXcale and a former serial Entrepreneur. After selling and integrating several monitoring tools for the biggest Spanish banks and telco with HP and CA, he co-founded two APM companies: Lucierna and Vikinguard. The former was acquired by SmartBear in 2013 and named by Gartner as Cool Vendor.
ABOUT LEANXCALE
LeanXcale is a startup making a NewSQL database. Since the blog is vendor agnostic, we do not talk about LeanXcale itself. Readers interested in LeanXcale can visit the LeanXcale website.