

This article explains how LeanXcale is deployed to adjust its components to different types of workloads. LeanXcale is a database that supports multiple interfaces, such as SQL or massive ingestions using direct Key-Values, that incorporate all its components but are deployed differently. For example, if the workload is primarily SQL queries, then the deployment should include enough Query Engine instances to manage all queries. The various layers that compose LeanXcale are first described, followed by an explanation of the different components within each layer. Finally, deployment configurations are reviewed based on specific use cases.
LEANXCALE STACK
LeanXcale provides a 3-layer stack:
- The first layer is the Query Engine that transforms SQL queries into a query plan comprised of executable algebraic operators over the datastore that moves data across these operators until producing the result of the original SQL query. The LeanXcale Query Engine supports the standard JDBC SQL interface for Java processes, SQLAlchemy for Python processes, and ODBC SQL for development in Microsoft Windows environments.
- The second component is the LeanXcale Key-Value Storage Engine, named KiVi, which was designed from scratch with a new architecture to enable optimal performance. This storage engine beats most other current Key-Value storage engines that allow transactions, as exemplified by a LeanXcale benchmark run to compare KiVi against DynamoDB. This Key-Value is accessed by the Query Engine to manipulate the stored data and offers an API for Java, Python, and C.
- The third layer is the Transaction Manager responsible for maintaining full ACID transactions and enables the system to scale as much as the workload requires.
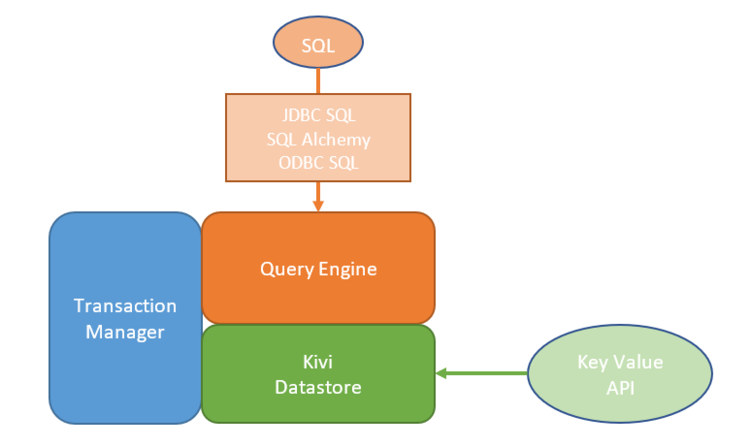
LEANXCALE COMPONENTS
The KiVi Datastore and Transaction Manager layers include multiple components.
The KiVi Key-Value storage engine has the KiVi metastore and KiVi datastore:
- KiVi metastore maintains the metadata structure that has all the required data to track in which KiVi datastore a tuple is held.
- KiVi datastore stores in a structured way all the tuples of the regions it has assigned. This datastore offers multi-versioning of the key-value to support the Snapshot Isolation level.
The Transaction Manager is composed of the following:
- The Mastermind component is responsible for maintaining system configuration, recovering all components in failure scenarios to keep the system working, managing in a distributed manner all transactions of the LeanXcale database.This is the primary component that enables the linear scalability by keeping the ACID transactions, which has been proven up to 100 nodes without tradeoffs in response times while supporting more workload.
- By default, LeanXcale offers the Snapshot Isolation level so that only write-write conflicts can occur. The Conflict Manager component is responsible for maintaining coherence between all write operations.
- The final component of the Transaction Manager includes two types of loggers that persist the data, a logger for the metadata that traces the metadata operations, and a Query Engine logger to persist all write transactions.
- Apache ZooKeeper is also incorporated to manage the active instances of the cluster.
LEANXCALE DEPLOYMENTS
By design, all LeanXcale components are distributed, allowing for multiple deployment configurations. Consequently, these components can be spread across multiple servers. However, for some scenarios, such as ensuring High Availability, the components must be replicated and run on different nodes. In this section, multiple deployment configurations are explained based on use cases to adapt them to the workload that LeanXcale manages.
Standalone deployment
Some use cases for LeanXcale do not require processing much data, so these installations need only one node to run all components. A single instance of the components is launched on the same node. While the minimum hardware requirement for LeanXcale is 3 GB RAM, this limited amount can impact the performance if the workload grows. Therefore, the components feature a configurable memory to adapt to the hardware configuration of the node.
Distributed deployment
A distributed deployment is the most common configuration LeanXcale provides. By default, LeanXcale distinguishes two node types of the metastore and datastore nodes. The metastore node includes the components that contain the metadata information, and the datastore node includes those that store or process the data. This deployment configuration provides an easy-to-scale capability by increasing the number of datastore nodes. At least one metastore node and one datastore node are required with which most workloads can be managed. If the deployment requires more computing or storing capabilities to manage a larger workload, then a new datastore node can easily be added. In this scenario, the data from the previous datastore node is automatically distributed across the new node. The previous article demonstrates how this deployment can be applied with up to one hundred nodes while obtaining linear scalability from the LeanXcale database.
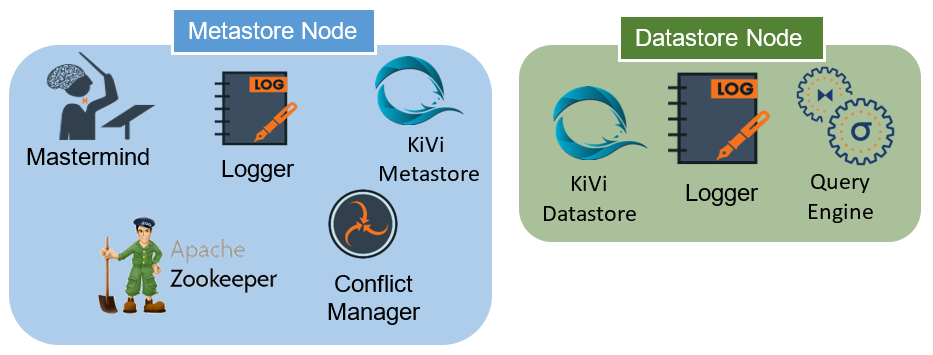
High Availability Deployment
LeanXcale recommends the High Availability deployment configuration for production environments as it supports even full machine failures based on the replication of some systems.
This deployment does require more nodes, so the price of the hardware resources increases to incorporate at least two metastore nodes and two datastore nodes. In most cases, one of these nodes can function as a metastore and datastore node simultaneously to only require at least three machines to perform, as is necessary for the consensus protocol. Depending on the distribution protocol used by the components, some have active/passive replication, and others directly distribute the workload to increase what can be accepted by the deployment. For example, Mastermind features an active/passive replication with only a single instance working while promoting the passive instance to active only when the system encounters a crash and no longer has an active Mastermind instance. However, each Conflict Manager instance resolves many write-write conflicts by distributing the load of the client across multiple Conflict Manager instances.
The Datastore nodes have replication on the loggers, and all the regions of the KiVi datastore instances are replicated across multiple instances. Each Query Engine functions as an independent instance, so it needs no replication because they access the same datastore engine.
Meta, Data, and Compute Nodes
For scenarios where the workload cannot be defined before deployment, LeanXcale recommends including three node types:
- Metadata node for all components that maintain the metadata information.
- Datastore node with its fast I/O bandwidth for the KiVi datastore and Logger components.
- Compute nodes with powerful CPUs to run the Query Engine instances.
This deployment configuration supports high availability by having at least two instances of each node type.
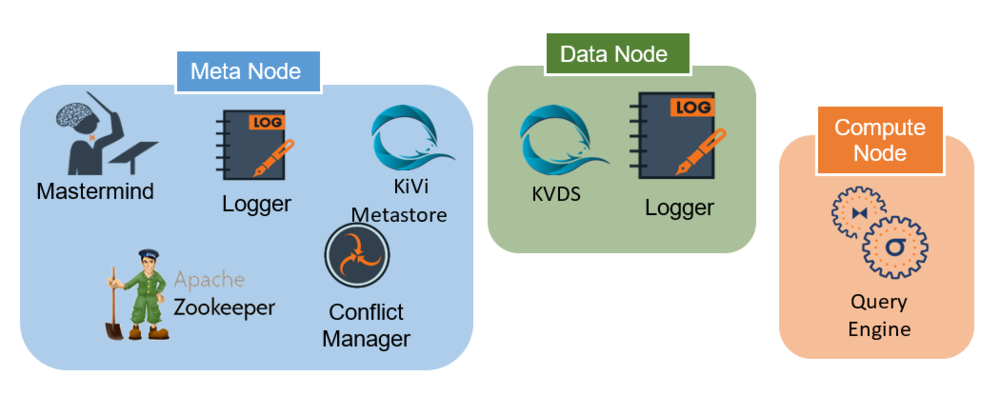
As a key benefit, this deployment easily adapts to any workload that LeanXcale might encounter. For example, if a workload uses mostly the KiVi direct API to access the storing engine and avoid the Query Engine overhead, the deployment may require multiple datastore nodes and only one compute node. The datastore node manages all KiVi direct API workloads, and the system remains prepared for any analytic SQL query that must be performed.
CONCLUSION
With the distributed design of its components, LeanXcale can run on multiple deployment configurations to support the best approach for any workload. This capability enables LeanXcale to adapt to multiple scenarios that opens new business opportunities as well as making it a great option for growing companies that do not yet have a well-defined workload. Companies using LeanXcale today have leveraged this adaptability, and you can read more about these deployments by our customers and request a demo to discuss the best deployment configuration for your business needs.
WRITTEN BY

Diego Burgos Sancho
Software Engineer at LeanXcale
After working at the Distributed Systems Lab at the Technical University of Madrid as a computer scientist, I joined LeanXcale to build one of the most interesting distributed systems ever developed. At LeanXcale, I’m performing research through an industrial PhD at the Technical University of Madrid.