

Scalability & Performance
What is scalability? Scalability is an overloaded term that has been perverted by technical marketing to confuse potential customers. Every system today would be advertised as scalable although it is often not true. Scalability is the ability of a system to deliver better performance when the size of the system is increased with more resources. But what does better performance mean? Performance is also an overloaded term with different meanings depending on the context. The term is also misused in technical marketing. In databases, the two most important performance metrics are throughput and response time. It is important to define them in order to understand how they can be improved.
Throughput
Throughput is the number of operations per time unit a system can make (see Figure 1). In the case of a database, typical throughput measures are transactions/second, inserts/second, queries/second. It is important to understand that a throughput metric is given for a particular workload, software system and underlying hardware. Changing the workload might have a dramatic effect on the throughput. For instance, a workload might be limited by one resource, say CPU, and when the workload changes, it might become limited by another resource, say IO bandwidth. This workload change can typically slow down by more than an order magnitude the database throughput.
Response Time
Response time is the time from submitting an operation until receiving the answer (see Figure 2). It is important to define in which conditions the response time is measured. For operational databases, response time only makes sense to be measured while we inject a particular workload and the system is in steady state, delivering a stable throughput (see our blog post on measuring scalability and performance). For instance, one can measure the average response time of the transactions. If the workload contains different kinds of transactions, which is most common, averaging the response time per kind of transaction is more informative than just the global time. What is more, the average is not sufficient. What you actually need to know is the actual distribution of the response time. The average plus the percentiles (90%, 95% and 99%) provide a good insight on how the database behaves. However, you also need both throughput and response time for any given workload to understand how response time evolves with an increasing throughput.
Vertical vs. Horizontal Scalability (Scale Up vs. Scale Out)
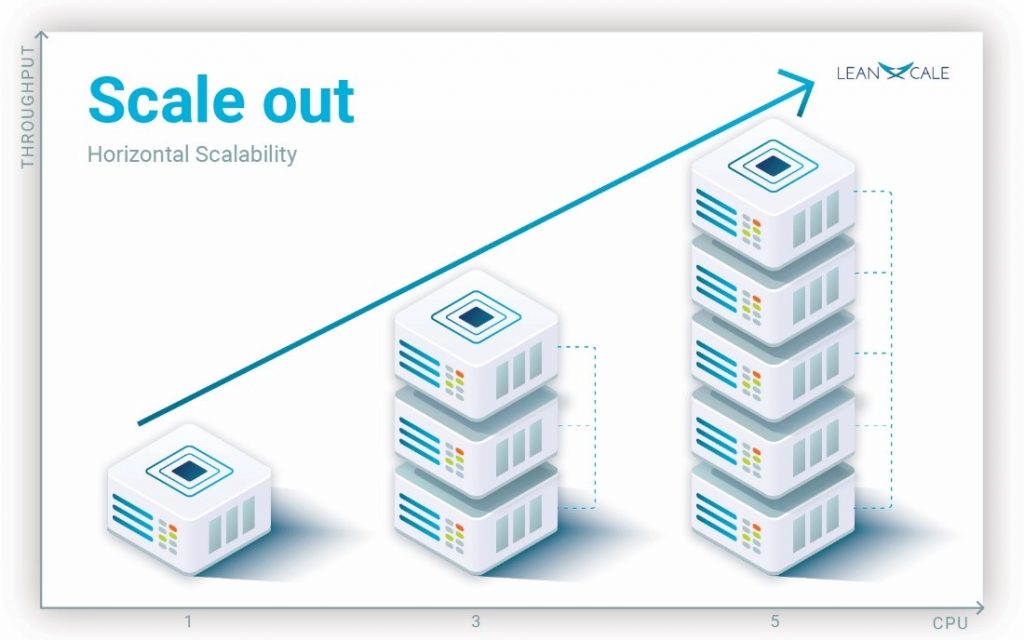
Coming back to the definition of scalability [Özsu & Valduriez 2020], we said that is the ability to deliver more throughput when we use more resources, but what does more resources mean? It depends on whether the system is centralized or distributed. Thus, scalability can be classified between vertical or horizontal, depending on what we mean by more resources. In a centralized system we can add more CPUs, more memory, more storage devices to increase computational resources (see our blog post on database architectures). We say a database scales vertically when it is able to provide more throughput with a bigger computer in terms of CPUs, memory and IO devices (see Figure 1).

Now, consider a distributed database running on a set of computers connected by a network that share nothing (see our blog post on shared nothing), i.e., on a computer cluster. In this case, we talk about horizontal scalability. A database scales horizontally when adding more nodes to the cluster yields more throughput (see Figure 2, each column is a cluster with each box being a server within the cluster).
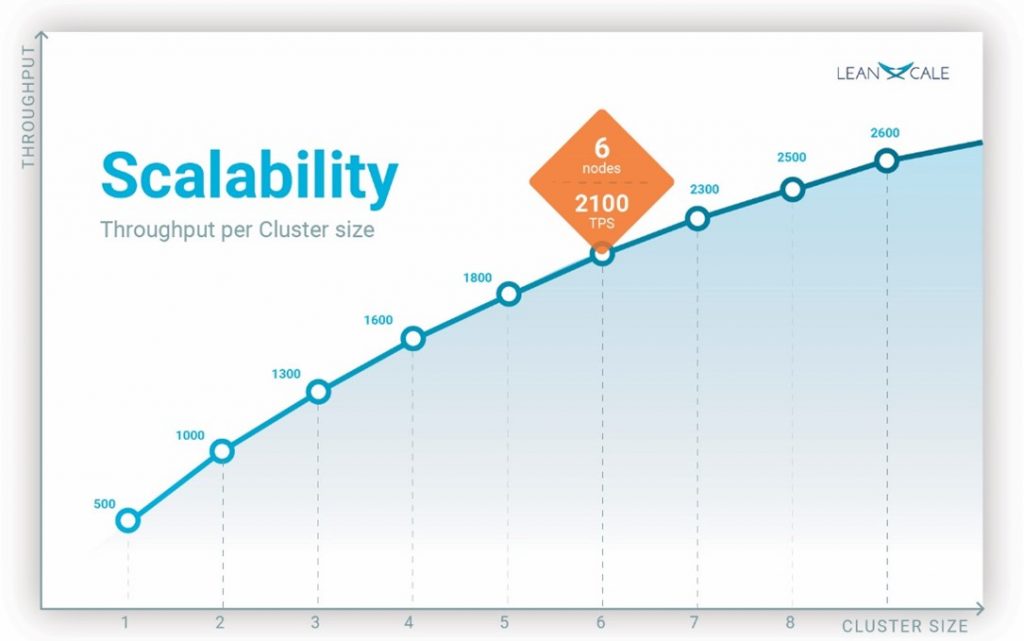
Scalability Graph
Figure 3 depicts a sample horizontal scalability of a distributed database. The scalability graph has in the x axis the cluster size in number of nodes and in the y axis the throughput. One node delivers a throughput of 500 txn/sec. By increasing the cluster size, we can observe how the total throughput of the cluster increases. With 2 nodes is almost 1,000 txn/sec, and with 9 nodes is around 2,600 txn/sec.
Speed Up
Another important aspect related to (and often confused with) scalability is speed up. Speed up is the ability to reduce response time by adding more resources. Again, we can do it vertically or horizontally. Speed up is often applied to batch processes or processes that are long and run in isolation. In databases, speed up is interesting in two cases. The most typical one is for large analytical queries that take a long time to be processed. They can be executed in isolation to exploit all resources, or in parallel with other workloads of analytical or operational nature. In Figure 4, we can see a sample of horizontal speed up. As we can see with one node, a query takes 325 seconds. When using two nodes the time is reduced to 200 seconds. With 5 nodes, the time has gone down to 20 seconds.

Scalability Factor
One major question one could ask: do all databases scale the same? or if not, can we measure it? For sure, all databases scale very differently. Even the same database will scale differently depending on the workload. Scalability can measured using the scalability factor: scale up for vertical scalability and scale out for horizontal scalability. The scalability factor gives the throughput normalized to the relative throughput of a single node. It can also be seen as the ratio between the throughput of a database with one resource and the same database with a number of resources, say n. That is, scalability factor = throughput (n resources) / throughput (one resource). In the case of horizontal scalability, we would use the throughput of a cluster with n nodes and a cluster with a single node to compute the ratio. For vertical scalability, we would do the same with the number of CPUs of a NUMA computer, throughput of one CPU vs. throughput of n CPUs. From now on, for the sake of clarity, we will just talk about horizontal scalability. The reader can easily translate the previous examples to deal with vertical scalability.
Types of Scalability
The first question that comes to mind when thinking about scalability is what optimal scalability is, and how scalability can vary. Scalability can be logarithmic or linear, but can be also null or even negative. We illustrate the different types of scalability with a scalability graph showing the scalability of a clustered database (see Figure 5). Linear scalability is the optimal case. It means that with a cluster of n nodes, you get n times the throughput of a single node. For instance, if a single node delivers 1,000 transactions per second, a cluster of 100 nodes delivers a throughput of 100,000 transactions per second. In many cases, databases exhibit sublinear scalability, although the most common case is that scalability is null for write workloads and logarithmic for read/write workloads. Some databases even deliver negative scalability, as adding more nodes to the system yields a throughput lower than with a single node.
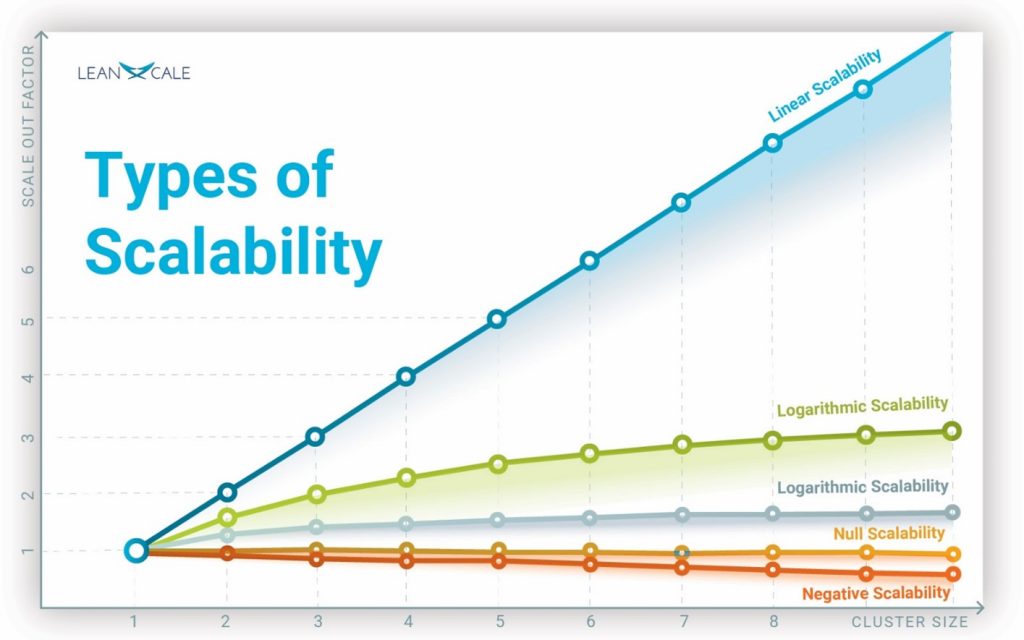
Databases with Logarithmic Scalability
Logarithmic scalability results from wasting capacity due to redundant work and/or contention. Let us look at two examples with logarithmic scalability. Open source databases such as MariaDB rely on an old line of research called scalable database replication, more commonly known today as cluster replication. Cluster replication inherently exhibits logarithmic scalability. The reason is that the writes in the workload are executed by all nodes. So only the read fraction of the workload provides some scalability (see our blog post on Cluster Replication that focuses on the scalability of cluster replication with a detailed analytical model that provides a mathematical formula to compute the throughput graph for cluster replication solutions). Another example of logarithmic scalability includes databases based on shared disk. In this case, logarithmic scalability stems from the need for a concurrency control protocol that locks disk pages to be written, which results in a substantial contention that increases with the cluster size.
Databases with Linear Scalability
Key-value stores (see our blog post on NoSQL) typically provide linear scalability because they are very simple, without addressing the hard problem of scaling transactional management (the so-called ACID properties). Transactional databases that exhibit linear scalability are very few. Since this blog series is vendor agnostic, we don’t discuss about particular database products. Almost virtually any database, even centralized, claims scalability. Through our series of posts devoted to scalability and benchmarking, the reader will be able to learn the rudiments to actually evaluate the scalability of different databases and understand how they behave and if they actually meet their requirements (see our blog post on How To Measure Scalability and Performance).
Types of Speed Up
Speed up can also show different behaviors, from null to linear. A linear speed up means that the response time obtained with a centralized system is divided by n in a cluster with n nodes. A null speed up means, for instance, that a given query always exhibits the same response time with one or more nodes. This is what happens in a distributed database without a parallel/OLAP query engine, that is, without intra-query parallelism. The reason is that with inter-query parallelism each node processes a subset of the queries, but each query can only be executed by a single node, so no speed up is possible for queries.
This is the case in cluster replication, having a bigger cluster does not help to lower the response time of an individual query. Why? Because a query will be processed at a single node of the cluster, having many other nodes in the cluster will not help to reduce its response time.
Main Takeaways
The two main metrics for measuring the performance of a database are throughput and response time. Throughput measures the number of operations (transactions, queries, inserts) per time unit. Response time measures how long it takes to execute a particular request (transaction, query, insert).
Scalability measures the ability of database to handle bigger loads with more resources. In distributed databases, more resources mean more nodes, and we talk about horizontal scalability. In a centralized database, more resources mean more CPUs, more memory, more disks, and we talk about vertical scalability.
Speed up is a related but different concept. Speed up refers to the ability to reduce the response time of large queries by adding more resources, again it can be horizontal for a distributed database or vertical for a centralized one. Scalability and speed up can be of different kinds. Negative and null are obviously of no interest. Logarithmic can be better but only for a few nodes. Linear scalability is actually the one that is optimal since each node added contributes the same in terms of additional load that can be handled.
References

[Özsu & Valduriez 2020] Tamer Özsu, Patrick Valduriez. Principles of Distributed Databases, 4th Edition, Springer, 2020.
Relevant posts from the blog

About this blog series
This blog series aims at educating database practitioners in topics commonly not well understood, often due to false or confusing marketing messages. The blog provides the foundations and tools to let the reader actually evaluate databases, learn their real capabilities and be able to compare the performance of the different alternatives for its targeted workload. The blog is vendor agnostic.
About the authors
- Dr. Ricardo Jimenez-Peris is the CEO and founder of LeanXcale. Before founding LeanXcale, he was for over 25 years a researcher in distributed databases director of the Distributed Systems Lab and university professor teaching distributed systems.
- Dr. Patrick Valduriez is a researcher at INRIA, co-author of the book “Principles of Distributed Databases” that has educated legions of students and engineers in this field and more recently, Scientific Advisor of LeanXcale.
About LeanXcale
LeanXcale is a startup making a NewSQL database. Since the blog is vendor agnostic, we do not talk about LeanXcale itself. Readers interested on LeanXcale can visit LeanXcale web site.